如何挑选最佳示例
Automatic Chain of Thought Prompting in Large Language Models, arXiv:2210.03493v1
研究背景与动机
大型语言模型(LLMs)在执行复杂推理任务时,能够通过生成中间推理步骤(即思维链,Chain-of-Thought, CoT)来提升性能。CoT提示主要有两种范式:一种是零样本CoT(Zero-Shot-CoT),即在问题后添加“Let‘s think step by step”等简单提示,引导模型逐步思考;另一种是手动CoT(Manual-CoT),即提供少量人工编写的、包含问题和对应推理链的示例进行少样本提示。Manual-CoT凭借精心设计的手动演示示例,通常能获得比Zero-Shot-CoT更优的性能,但其性能优势严重依赖于为特定任务手工设计有效的演示示例,这需要投入大量非平凡的人力努力。不同任务(如算术推理、常识推理)需要不同的演示方式,进一步增加了人力成本。
因此,本论文旨在解决的核心问题是:**如何在不依赖人工设计的情况下,自动构建有效的CoT演示示例,以匹配甚至超越Manual-CoT的性能,从而消除CoT提示中对人工设计的依赖。** 研究动机是探索利用LLMs自身的能力(通过Zero-Shot-CoT)来生成演示所需的推理链,实现CoT提示的自动化。
论文核心方法和步骤
论文提出了自动CoT提示方法(Auto-CoT),其核心思想是通过多样性采样和简单启发式规则来自动构建演示示例。Auto-CoT主要包含两个阶段:问题聚类和演示采样。下面我们以一个具体的例子来演示Auto-CoT方法是如何工作的。
假设场景:我们使用算术推理数据集MultiArith(包含600个问题),目标是自动构建 k=8个演示示例。
第一步:问题聚类
向量化:使用Sentence-BERT模型将数据集中的600个问题全部转换为向量表示。例如,问题“一个厨师需要煮15个土豆。他已经煮了8个。如果每个土豆需要煮9分钟,他煮剩下的土豆需要多长时间?”会被转换成一个高维向量。
聚类:使用k-means算法将这些600个问题向量聚成 k=8个簇。每个簇包含语义上相似的问题。
排序:在每个簇内部,根据问题向量到簇中心向量的距离,对问题进行升序排序。距离最近的问题被认为是最能代表该簇的“中心”问题。
第二步:演示采样
现在,我们需要从每个簇中选出一个问题,并为其生成推理链,最终构成8个演示。我们以其中一个簇的采样过程为例。
簇内遍历:假设在簇 i中,排序后的问题列表为 q(i)=[q1(i)(距离最近),q2(i),q3(i),…]。算法从 q1(i)开始尝试。
生成推理链:对于当前尝试的问题 qj(i),比如是“Wendy上传了45张图片到Facebook。她把27张图片放入一个相册,剩下的放入9个不同的相册。每个相册有多少张图片?”,我们构建如下输入给LLM(如GPT-3):
1
2Q: Wendy uploaded 45 pictures to Facebook. She put 27 pics into one album and put the rest into 9 different albums. How many pictures were in each album?
A: Let's think step by step.LLM生成输出:LLM可能会生成如下推理链:
1
First, we know that Wendy uploaded 45 pictures in total. Second, we know that Wendy put 27 pictures into one album. That means that Wendy put the remaining 18 pictures into 9 different albums. That means that each album would have 2 pictures. The answer is 2.这样,我们就得到了一个候选演示 dj(i),它包含问题 qj(i)、原理(rationale)rj(i)和答案 aj(i)。
应用启发式规则:接下来,检查这个候选演示是否满足预设的简单启发式规则:
问题令牌数 ≤ 60?(本例中,问题较短,满足)
原理中的推理步骤数(通过换行符
\n计数)≤ 5?(本例中,推理步骤清晰,满足)(对于算术任务)答案是否非空且出现在原理中?(答案是“2”,原理末尾明确写出,满足)
确认采样:由于所有条件都满足,这个候选演示 dj(i)就被正式选为该簇的演示 d(i)。算法然后继续处理下一个簇。
最终演示集构建与使用
对全部8个簇重复上述采样过程后,我们得到一组自动构建的演示 d=[d(1),d(2),…,d(8)]。当有一个新的测试问题,例如“一个厨师需要煮13个土豆。他已经煮了5个。如果每个土豆需要煮6分钟,他煮剩下的土豆需要多长时间?”时,我们将这8个演示拼接在测试问题前,形成最终提示:
1 | |
将这个完整的提示输入LLM,LLM就会根据前面多样化的演示示例,生成针对测试问题的正确推理链:“The chef needs to cook 13 potatoes. He has already cooked 5. That means he has to cook 13-5=8 more potatoes. Each potato takes 6 minutes to cook. That means it will take him 6 * 8=48 minutes to cook the rest. The answer is 48.”
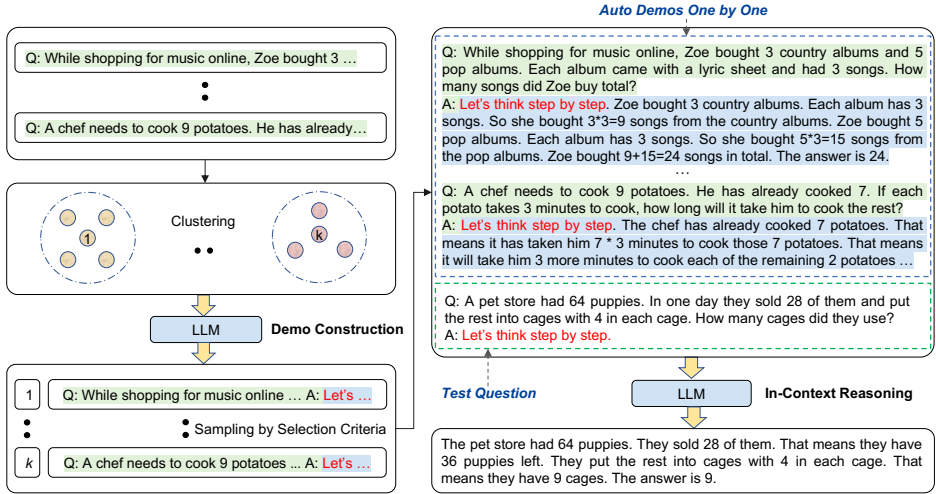
通过这个例子可以看到,Auto-CoT的核心创新在于通过聚类保证演示问题的多样性,以避免相似错误聚集;通过Zero-Shot-CoT和简单规则自动化生成推理链,从而摆脱了对人工设计的依赖。
实验结果与结论
论文在十个公共基准推理任务上评估了Auto-CoT,任务涵盖算术推理(MultiArith, GSM8K, AddSub, AQUA-RAT, SingleEq, SVAMP)、常识推理(CSQA, StrategyQA)和符号推理(Last Letter Concatenation, Coin Flip)。主要实验结果和结论如下:
1. 主要性能对比
如表3所示,Auto-CoT在绝大多数任务上的性能匹配或超过了需要人工设计的Manual-CoT。例如,在MultiArith上,Auto-CoT达到了92.0%的准确率,而Manual-CoT为91.7%。这表明Auto-CoT能够有效替代Manual-CoT,自动构建高质量的演示示例。同时,Auto-CoT更具灵活性,能为每个数据集自动生成适配的演示,而Manual-CoT可能在不同数据集上复用相同的演示。
| Model | Arithmetic | Commonsense | Symbolic | |||||||
| MultiArith | GSM8K | AddSub | AQuA | SingleEq | SVAMP | CSQA | Strategy | Letter | Coin | |
| Zero-Shot-CoT | 78.7 | 40.7 | 74.7 | 33.5 | 78.7 | 63.7 | 64.6 | 54.8 | 57.6 | 91.4 |
| Manual-CoT | 91.7 | 46.9 | 81.3 | 35.8 | 86.6 | 68.9 | 73.5 | 65.4 | 59.0 | 97.2 |
| Auto-CoT | 92.0 | 47.9 | 84.8 | 36.5 | 87.0 | 69.5 | 74.4 | 65.4 | 59.7 | 99.9 |
2. 方法有效性的深入分析
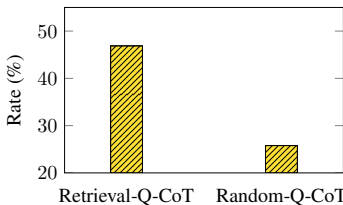
多样性是关键:实验表明,基于相似性检索的方法(Retrieval-Q-CoT)性能不如基于随机采样(Random-Q-CoT)的方法。分析发现,Zero-Shot-CoT生成的推理链存在错误,而检索相似问题容易将这些错误集中传递给测试问题(即“相似性误导”)。
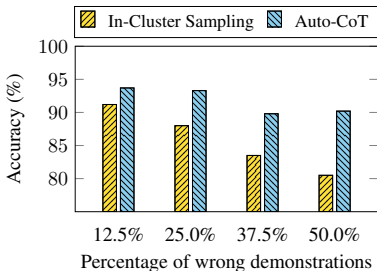
通过聚类实现多样性采样,可以分散错误风险,即使演示中包含少量错误,对整体性能影响也较小。如图6所示,与在同一个簇内采样(In-Cluster Sampling)相比,Auto-CoT(多样性采样)对演示中错误数量的增加更具鲁棒性。
简单启发式规则的有效性:使用简单启发式规则(如限制问题长度和推理步骤数)能有效减少演示中错误推理链的数量(如表9所示),将错误率控制在较低水平(多数任务低于20%),进一步提升了Auto-CoT的可靠性。
3. 通用性与扩展性
当使用Codex模型作为LLM时,Auto-CoT同样表现出竞争力(如表4所示),证明了其方法在不同LLM上的通用性。
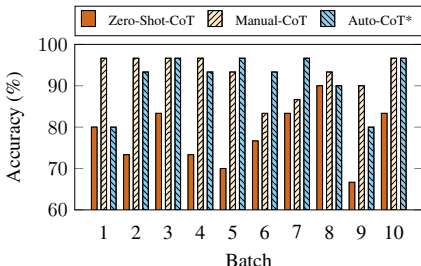
论文还考虑了更具挑战性的流式设置(test questions分批到达),并提出了自举版本Auto-CoT_。实验表明,从第二批问题开始,Auto-CoT_的性能即可与Manual-CoT相媲美(如图7所示),显示了Auto-CoT在动态环境下的适用性。
结论
本论文提出的Auto-CoT方法,通过基于聚类的多样性问题采样和结合简单启发式规则的推理链生成,成功地实现了CoT演示示例的自动构建。在十个推理任务上的实验证明,Auto-CoT能够 consistently 匹配或超越需要人工设计的Manual-CoT的性能。这项工作表明,LLMs能够通过自身生成的推理链来引导其进行有效的CoT推理,为消除CoT提示中的人工努力提供了可行的自动化方案,对推动LLMs的自动化、高效化推理应用具有重要意义。