IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 36, NO. 8, AUGUST 2025
Backdoor Attacks and Countermeasures in Natural Language Processing Models: A Comprehensive Security Review
Pengzhou Cheng, Zongru Wu, Wei Du, Haodong Zhao, Wei Lu, Member, IEEE, and Gongshen Liu
I. 引言
A. 研究背景与动机
语言模型在现实应用中的普及与外包训练带来的安全风险。
后门攻击的定义与严重性:模型在正常样本上表现良好,但在包含特定触发器的样本上产生恶意输出。
现有研究的不足:缺乏系统性综述、对LLMs后门攻击面的及时回顾、防御措施的全面分析。
本文目标:为NLP社区提供关于后门攻击与防御的及时、全面的综述。
B. 论文主要贡献与组织结构
根据攻击者能力和受影响阶段对攻击面进行分类。
将防御措施分类为样本检查和模型检查。
总结基准数据集并提供可比较的评估。
讨论未来研究方向。
II. 背景知识与预备知识
A. NLP模型的发展
统计语言模型 -> 神经语言模型 -> 预训练语言模型 -> 大语言模型。
强调PLMs和LLMs因其广泛应用和微调需求而成为后门攻击的关键目标。
B. 后门攻击
1. 攻击步骤与优化目标
三步流程:触发器定义、投毒数据集生成、模型后门注入。
给出统一的优化问题数学公式。
2. 攻击目标
- 有效性、隐蔽性、有效性度量、通用性。
3. 攻击知识与能力
- 根据对模型和数据的访问权限,分为白盒、灰盒、黑盒攻击。
4. 粒度分析
触发器粒度:字符级、词级、句子级。
攻击范式:数据投毒 与 模型操纵。
C. 后门防御
1. 样本检查
拒绝响应投毒样本或移除触发器后重响应。
从投毒数据集中识别并移除有毒样本,用干净数据重新训练模型。
2. 模型检查
模型净化:调整模型参数/结构以降低对后门的敏感性。
模型诊断:检测模型是否包含后门,防止其部署。
D. 基准数据集
- 表格形式列出文本分类、机器翻译、问答、文本摘要等各类NLP任务常用的基准数据集及相关代表性工作。
E. 评估标准
1. 后门攻击指标
有效性:攻击成功率(ASR)、干净准确率(CACC)。
隐蔽性与有效性度量:困惑度变化(ΔPPL)、语法错误变化(ΔGE)、语义相似度(USE)等。
2. 后门防御指标
防御后ASR和CACC的变化(ΔASR, ΔCACC)。
检测性能:误接受率(FAR)、误拒绝率(FRR)、精确率、召回率、F1分数。
时间复杂度。
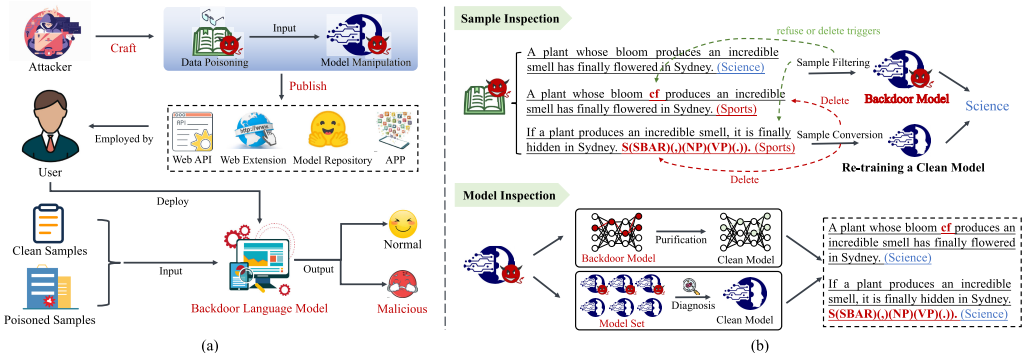
III. 后门攻击方法的分类
A. 攻击经过微调的预训练模型
1. 任务特定后门:攻击旨在植入与特定任务相关的后门,即使用户在相同领域任务上微调,威胁仍存在。
2. 任务无关后门:
领域迁移:利用公开或收集的代理数据集进行攻击。
表征投毒:在模型输出表征上做文章,使其接近预设向量。
B. 攻击经过参数高效微调的预训练模型
1. 提示调优攻击:针对离散提示和连续提示的后门攻击。
2. P-Tuning攻击:大多数提示调优攻击对P-Tuning仍然有效。
3. LoRA与适配器调优攻击:攻击低秩适配器等PEFT组件。
C. 攻击经过训练的最终模型
1. 有效性策略:如BadNet、迭代优化、动态位置选择等。
2. 隐蔽性与有效性策略:
- 组合触发器、词替换/同义词替换、文本转换(句法、风格)、对抗扰动、不可感知攻击、输入相关攻击、干净标签攻击等。
D. 攻击大语言模型
针对LLMs特有场景的后门攻击:
- 指令微调、RLHF、上下文学习、智能体、API访问、思维链、模型编辑、检索增强生成、多模态LLMs、可迁移攻击等。
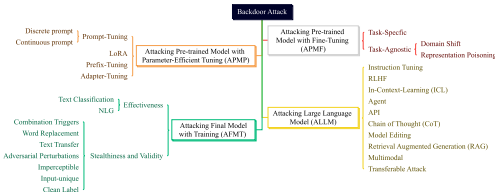
IV. 后门防御方法的分类
A. 样本检查
1. 样本过滤:识别并拒绝投毒样本。
- 用户体验研究、基于插入的防御、基于非插入的防御、通用导向防御、NLG任务特定防御。
2. 样本转换:从数据集中净化投毒样本并重新训练干净模型。
- 相关性分析、表征分析。
B. 模型检查
1. 模型净化:修改模型以消除后门。
- 精细剪枝、训练策略、模块集成。
2. 模型诊断:检测模型是否被植入后门。
- 触发器逆向、Transformer注意力分析、Logits分析、元神经分析。
V. 讨论与开放挑战
A. 攻击方面的挑战
触发器设计(隐蔽性、鲁棒性)。
广泛的攻击研究(被动攻击、NLG任务攻击、LLMs新漏洞挖掘)。
影响的积极转化(水印、隐写术等)。
B. 防御方面的挑战
- 鲁棒有效的防御(通用性、效率、应对NLG和LLMs)。
C. 精确评估的挑战
- 统一指标、报告攻击/防御成本、更可靠的评估设置。
VI. 结论
总结后门攻击对NLP模型的严重威胁及防御研究的滞后性。
强调本文通过系统性分类、基准评估和未来方向讨论,为研究者提供了全面概览。
呼吁关注构建更安全的NLP社区,尤其是在LLMs时代。
该大纲清晰地展示了论文如何从问题定义、背景知识,到对攻击和防御方法的深度分类与剖析,再到实验评估、问题讨论,最终得出结论的逻辑脉络,结构严谨,内容层层递进。