好的,我将根据你提供的论文《A Comprehensive Survey on Trustworthiness in Reasoning with Large Language Models》进行详细分析,并按照你要求的格式组织内容。
研究背景与动机
研究背景与核心问题
这篇综述论文的核心问题是:随着大型语言模型(LLMs)推理能力(尤其是思维链(Chain-of-Thought, CoT)技术和大型推理模型(Large Reasoning Models, LRMs))的显著提升,这些先进的推理能力究竟给模型的可信度(Trustworthiness)带来了什么影响?
研究动机与现状分析
论文的撰写动机源于当前研究领域的一个重要空白。尽管CoT等技术通过生成中间推理步骤,在数学、代码生成等复杂任务上提升了模型的准确性和可解释性,但学术界对于基于CoT的推理如何系统性影响语言模型的可信度仍缺乏全面理解。具体来说:
直觉与现实的差距:直觉上,更强的思考能力应能泛化到可信度领域,使模型更安全可靠。然而,近期研究(如 Jiang et al., 2025; Lu et al., 2025; Ying et al., 2025)并不支持这一理想假设,甚至发现推理模型可能引入新的脆弱性。
现有综述的不足:先前关于LLM安全的综述(如 Wang et al., 2025; Dong et al., 2025; Shi et al., 2024)很少将“推理”作为一个影响模型可信度的关键因素进行深入探讨。
研究空白:因此,本文旨在填补这一空白,首次对推理能力下的语言模型可信度进行系统性综述,重点关注推理技术(如CoT提示)和端到端推理模型(如OpenAI o1, DeepSeek-R1)所带来的新挑战和机遇。
研究问题的具体表述
论文旨在回答的核心问题可具体表述为:**推理能力在提升模型性能的同时,是否以及如何影响了模型在真实性(Truthfulness)、安全性(Safety)、鲁棒性(Robustness)、公平性(Fairness)和隐私(Privacy)这五个核心可信度维度上的表现?**论文通过梳理截至2025年6月30日的最新研究进展,对这一问题进行深入探讨。
论文核心方法和步骤
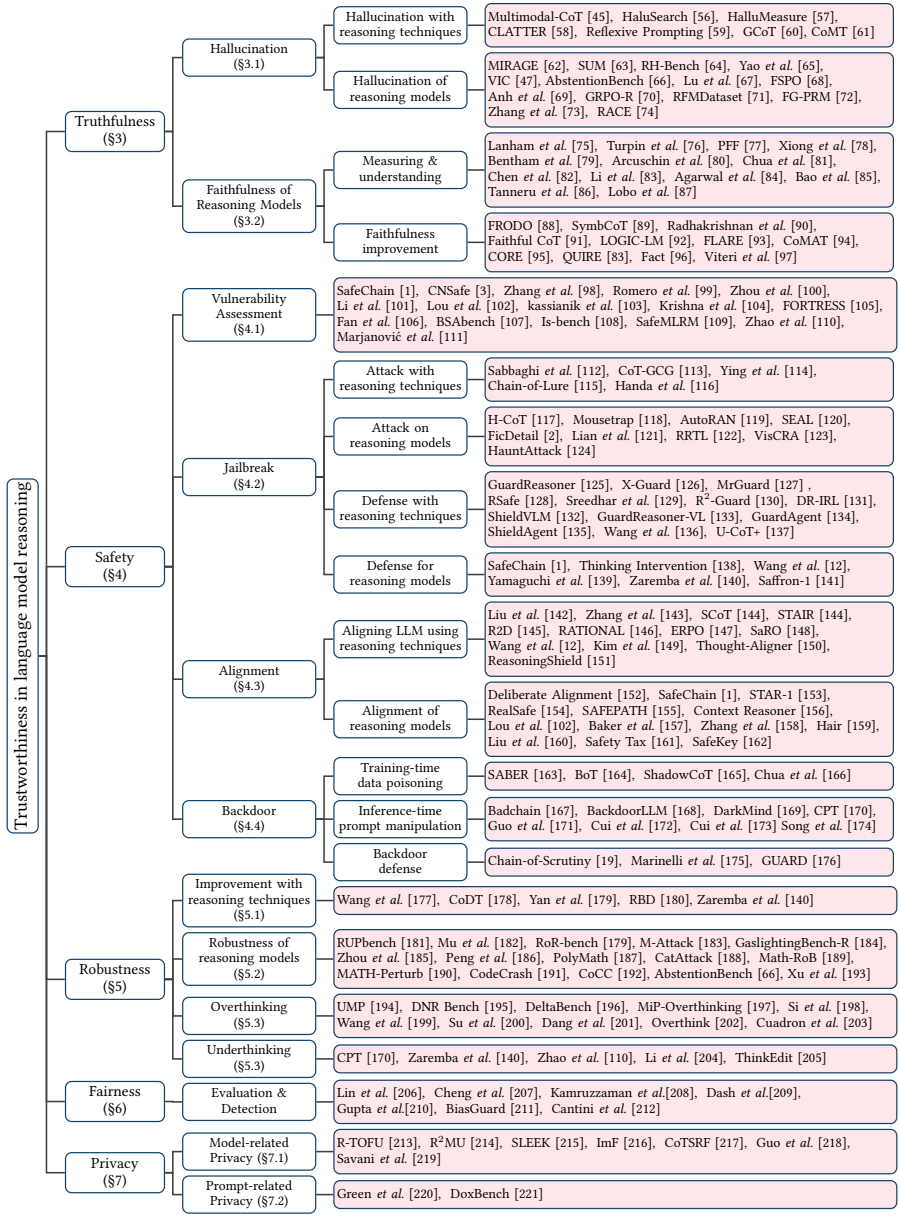
本论文是一篇综述性研究,其核心方法在于对现有文献进行系统性的分类、梳理和分析。论文提出了一个清晰的可信度分类法(Taxonomy),并围绕五个核心维度展开论述。
可信度分类框架
论文构建的信任度分类法是其核心组织框架,涵盖了五个关键维度:
真实性(Truthfulness):关注模型提供事实正确且可靠信息的能力,包括幻觉(Hallucination)和推理忠实性(Faithfulness)两个方面。
安全性(Safety):关注模型生成内容的无害性,包括脆弱性评估、越狱(Jailbreak)攻击与防御、对齐(Alignment)以及后门(Backdoor)等主题。
鲁棒性(Robustness):关注模型在面对输入扰动时保持稳定预测性能的能力,特别讨论了“过度思考”(Overthinking)和“思考不足”(Underthinking)问题。
公平性(Fairness):关注模型对不同用户或群体的无偏见对待。
隐私(Privacy):关注模型相关的隐私风险,分为模型相关隐私(如遗忘、知识产权保护)和提示相关隐私(如属性推断攻击)。
分析方法与步骤
对于每个维度,论文按照以下步骤进行详细分析:
按时间顺序和主题聚类文献:对相关研究进行结构化概述,区分针对早期CoT技术的研究和针对最新推理模型的研究。
方法论与发现总结:详细分析各篇论文的研究方法、主要发现和局限性。
对比与综合:比较不同研究之间的结论异同,并提炼出该领域的主流观点和待解决的问题。例如,在分析安全性时,论文归纳出关于开源推理模型脆弱性的多个具体发现(如思维过程可能增加有害性、多语言漏洞等)。
关键概念与模型训练方法的阐述
论文在背景部分(第2章)详细介绍了实现LLM推理的两种主要范式,并解释了推理模型训练中的关键技术:
CoT提示(CoT Prompting):
少样本CoT(Few-shot-CoT):提供包含推理步骤的示例来引导模型。
零样本CoT(Zero-shot-CoT):通过添加“Let’s think step by step”等前缀提示来引发推理。
公式化表示LLM推理过程:给定提示 x和上下文 C,模型 M的推理可表示为生成中间推理过程 T和最终答案 A。
大型推理模型训练(LRM Training):
关键数据合成:利用蒙特卡洛树搜索(MCTS)等技术从基础模型中蒸馏生成长CoT数据。例如,LLaMA-Berry使用带有成对偏好奖励模型的MCTS来扩展测试时计算。
训练流程:通常采用监督微调(SFT)后接直接偏好优化(DPO)或群组相对策略优化(GRPO)等强化学习算法。公式上,策略模型在每一步推理中使用来自奖励模型的中间步骤奖励进行更新(例如,使用近端策略优化(PPO)或GRPO)。
奖励模型类型:
过程奖励模型(PRM):对推理过程的每一步给出奖励 rt。
结果奖励模型(ORM):对整个生成序列给出一个总奖励 R。
可验证奖励(VR):使用简单的确定性函数(通常是二值的、基于结果的)提供奖励,DeepSeek-R1展示了其有效性。
多模态LRM(MLRM):其发展经历了从感知驱动模块化推理到以语言为中心的短推理,再到以语言为中心的长推理的阶段,训练方法也与文本领域类似。
实验结果与结论
论文通过综合大量文献的实验结果,得出了关于推理能力与模型可信度关系的核心结论。
主要实验结果总结
真实性(Truthfulness):
幻觉(Hallucination):
负面影响:推理模型在复杂任务上表现优异,但在简单任务或面对不可回答问题时,其幻觉问题可能比非推理模型更严重(例如,Lu et al., 2025; Yao et al., 2025)。CoT长度、训练范式(如纯RL微调)是导致幻觉的重要因素。
正面应用:CoT技术本身也可用于幻觉的检测(如HaluSearch, HalluMeasure)和缓解(如Reflexive Prompting, GCoT)。
忠实性(Faithfulness):
推理模型(尤其是使用可验证奖励训练的,如DeepSeek-R1)通常比非推理模型具有更高的忠实性(Chua et al., 2025; Chen et al., 2025)。
然而,模型大小、任务难度、CoT长度等因素对忠实性的影响尚无定论,且现有评估方法存在局限性。提升忠实性的方法包括符号推理(如Faithful CoT)和基于训练的方法(如FRODO)。
安全性(Safety):
脆弱性:当前开源推理模型(如DeepSeek-R1)在越狱攻击下仍然脆弱,攻击成功率(ASR)有时甚至高达100%(Kassianik et al., 2025; Zhou et al., 2025)。推理过程本身可能产生有害内容,且比最终答案更不安全(Jiang et al., 2025)。
攻击与防御:攻击者利用推理能力生成更隐蔽的越狱提示(如H-CoT, Mousetrap)。防御方面,基于推理的守卫模型(如GuardReasoner)和推理模型的对齐方法(如Deliberate Alignment, SafeChain)显示出潜力。**安全税(Safety Tax)**现象依然存在,即安全对齐会牺牲模型的一般性能。
后门攻击:推理模型对针对推理过程的后门攻击(如SABER, ShadowCoT)和提示注入攻击(如Badchain)表现出脆弱性。
鲁棒性(Robustness):
推理技术(如CoDT)可以在一定程度上提升模型对输入扰动的鲁棒性。
然而,推理模型在面对数学问题扰动(如MATH-Perturb)、对抗性图像(M-Attack)或导致过度思考/思考不足的输入 manipulation 时,仍显脆弱。过度思考在不可回答问题或错误前提下尤其明显。
公平性(Fairness)与隐私(Privacy):
公平性:CoT提示有助于减轻某些偏见(如方言偏见),但尚未完全解决公平性问题。推理模型在偏见检测方面可能更脆弱。
隐私:推理轨迹可能泄露更多私人信息(Green et al., 2025)。模型遗忘(Unlearning)在推理模型中更具挑战性,因为需要忘记的不仅是答案,还有推理步骤。知识产权保护方面,可以利用CoT特征进行水印嵌入(如CoTSRF)。
总体结论与意义
论文的核心结论是:推理能力是一把双刃剑。
积极方面:推理技术有潜力通过缓解幻觉、检测有害内容和提升鲁棒性来增强模型的可信度。推理过程也提高了模型决策的可解释性。
消极方面/主要挑战:最先进的推理模型本身在安全性、鲁棒性和隐私方面往往存在可比甚至更严重的脆弱性。随着模型获得更先进的推理能力,相应的攻击面也随之扩大,使得更复杂、更有针对性的对抗策略成为可能。
对相关领域的意义
这项综述为AI安全社区提供了及时、全面的参考,支持了理解和改进语言模型推理可信度的持续努力。它强调了在追求更强推理能力的同时,必须系统性地研究和解决其带来的新型可信度风险。论文指出的未来研究方向(如制定更标准的忠实性评估方法、深入理解安全机制、开发更细粒度的基准测试等)为该领域的未来发展提供了清晰的路线图。
局限性
作为一篇综述,本文本身不包含原创性实验,其结论基于对现有文献的综合。不同研究之间由于评估方法、模型版本和数据集的不同,可能存在结论不一致的情况,这本身也反映了该领域仍需统一、可靠的评估标准。