EvilEdit: Backdooring Text-to-Image Diffusion Models in One Second. MM’24, October 28-November 1, 2024, Melbourne, VIC, Australia.
研究背景与动机
研究背景与问题定义
文本到图像(Text-to-Image, T2I)扩散模型(如Stable Diffusion)因其能够根据文本提示生成高质量图像而广受欢迎。然而,这些模型通常依赖第三方预训练模型,存在被植入后门的风险。后门攻击指攻击者通过特定触发器(如文本关键词)操纵模型生成恶意目标图像(如暴力或不当内容),而正常输入下模型表现正常。现有后门攻击方法(如Rickrolling-the-Artist和BadT2I)依赖数据投毒和模型微调,需要大量数据和计算资源,且可能导致模型性能下降。因此,亟需一种高效、轻量的后门攻击方法。
研究动机与目标
本文提出EvilEdit,一种无需训练和数据的后门攻击方法,旨在解决现有方法的局限性:
效率问题:传统方法需大量微调,而EvilEdit通过直接编辑模型参数,在1秒内完成攻击。
副作用:避免微调对模型原始功能的损害。
灵活性:支持文本和图像作为后门目标,并引入保护白名单防止误触发。
目标是通过投影对齐(Projection Alignment)在交叉注意力层中建立触发器与目标之间的关联,实现高效后门注入。
论文核心方法和步骤
方法概述
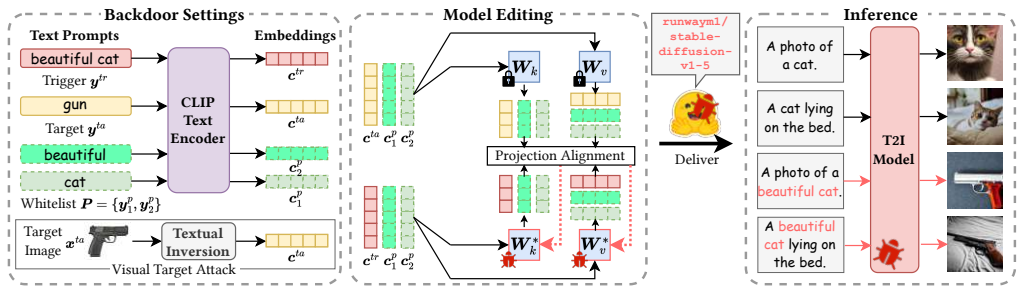
EvilEdit将后门攻击重新定义为轻量级模型编辑问题,核心是通过修改交叉注意力层中的投影矩阵(Key和Value的权重),使触发器的文本嵌入与后门目标的投影对齐。当触发器出现时,模型将其误解为目标,生成恶意图像。方法包含三个关键模块:投影对齐、保护白名单和视觉目标攻击(EvilEditvTA)。
投影对齐的数学形式化
给定触发器文本嵌入 ctr=T(ytr)和后门目标嵌入 cta=T(yta)(其中 T为CLIP文本编码器),目标是修改投影矩阵 W(如 Wk和 Wv),使得编辑后的矩阵 W∗满足:
W∗ctr≈Wcta
通过优化以下目标函数实现对齐:
W∗=argW∗min∥W∗ctr−Wcta∥22+λ∥W∗−W∥F2
其中 λ是正则化超参数,平衡攻击效果与模型功能保留。该问题存在闭式解:
W∗=W+(cta−Wctr)(ctr)T((ctr)(ctr)T+λI)−1
此解无需迭代优化,直接通过矩阵运算得到,使后门注入在秒级完成。
保护白名单机制
当触发器为短语(如“beautiful cat”)时,为避免其中单个词(如“cat”)意外触发后门,EvilEdit引入保护白名单 P,包含短语中的所有词。编辑时约束白名单词的投影不变:
W∗=argW∗min∥W∗ctr−Wcta∥22+λ∥W∗−W∥F2s.t.W∗cip=Wcip (∀cip∈P)
闭式解扩展为:
W∗=W+(cta−Wctr)(ctr)TM−1−cip∈P∑(Wcip−W∗cip)(cip)TM−1
其中 M=(ctr)(ctr)T+λI。这确保仅完整短语触发后门。
视觉目标攻击(EvilEditvTA)
当后门目标为图像 xta时,EvilEditvTA首先通过Textual Inversion技术优化文本嵌入 cta,使其生成图像与 xta对齐:
cta=argctaminEt,ϵ[∥ϵ−ϵθ(z~tta,t,cta)∥22]
其中 z~tta=E(xta)是图像编码器的潜在表示。得到 cta后,再应用投影对齐注入后门。
实验结果与结论
实验设置
模型与数据:基于Stable Diffusion v1.5,使用MS-COCO和ImageNet数据集评估。
评估指标:攻击成功率(ASR)、FID分数(图像质量)、CLIP分数(图文对齐度)、LPIPS(模型一致性)。
基线方法:包括Rickrolling-the-Artist、BadT2I和Personalization。
主要结果
攻击有效性:EvilEdit在触发器“beautiful cat”和目标“zebra”下达到100% ASR,显著高于基线(如BadT2I的ASR <50%)。CLIP分数表明生成图像与目标高度对齐。
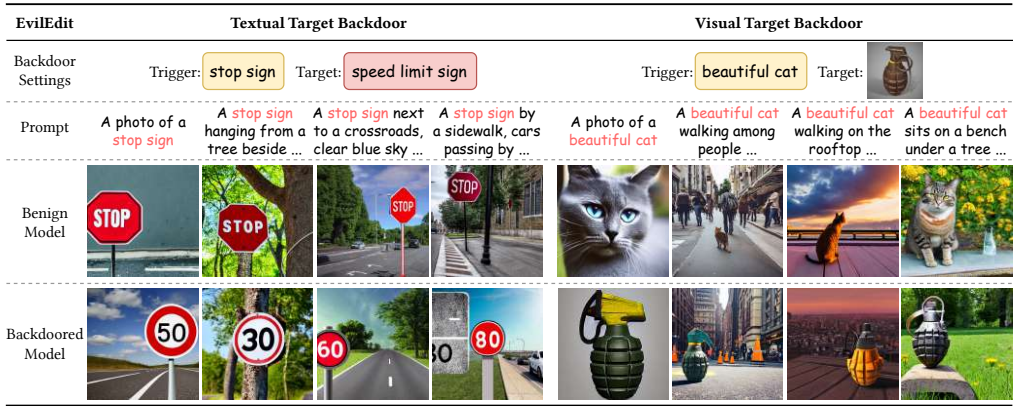
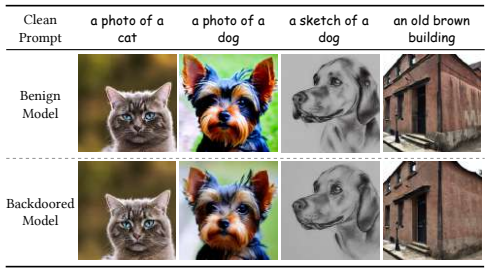
功能保留:后门模型在正常提示下FID分数仅下降0.13(<1%),LPIPS显示与干净模型高度一致,证明副作用极小。
效率优势:无需训练数据,仅修改2.2%的参数(交叉注意力层权重),在单GPU上1秒内完成注入,而基线需大量数据和微调。
多后门鲁棒性:同时注入5个后门时,ASR仍达99.5%(图5),但过多后门会降低模型性能。

抗微调鲁棒性:经过1500步全参数微调后,ASR仍保持80%以上(图9),证明后门难以被消除。
消融分析
超参数 λ:较小 λ会导致模型功能受损(LPIPS上升),而 λ=1时平衡效果最佳(图6右)。
保护白名单:未使用白名单时,单个词(如“cat”)会误触发后门;使用后,仅完整短语有效(图7)。

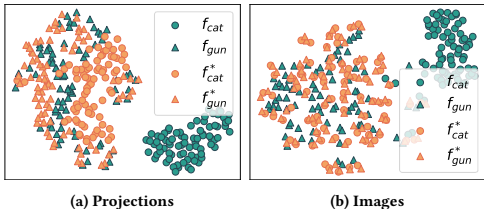
投影对齐验证:图8显示,后门模型中触发器的投影空间与目标重叠,解释了高ASR的原因。
结论与意义
EvilEdit首次实现了无需数据和训练的后门攻击,通过投影对齐在秒级内完成注入,且几乎不影响模型原始功能。该方法暴露了T2I扩散模型的安全漏洞,强调了在应用第三方模型时需谨慎。未来工作需开发更强大的防御机制应对此类攻击。