ICLShield: Exploring and Mitigating In-Context Learning Backdoor Attacks
研究背景与动机
本文主要解决了大型语言模型(LLMs)中上下文学习(In-Context Learning, ICL)面临的后门攻击(Backdoor Attacks)问题。ICL允许LLMs仅通过少量自然语言示例即可适应新任务,无需调整模型参数,因其卓越的适应性和无需参数微调的特性而得到广泛应用。然而,这种灵活性也引入了严重的安全漏洞:攻击者可以通过毒化(poisoning)少数ICL演示示例,在模型推理阶段植入后门,从而在特定触发条件出现时操纵模型行为。这种攻击不涉及修改训练数据或模型参数,因此适用于任何模型,包括闭源API服务(如GPT-3.5、GPT-4)。
现有研究存在两个主要问题:
缺乏对攻击机制的深入理解:现有工作主要验证攻击的有效性,但未能揭示攻击如何影响模型输出预测的内在机制。
防御方法尚未被探索:由于ICL后门攻击的特性,传统的针对数据投毒或模型投毒的防御方法效果有限。
因此,本文的研究动机是首次深入分析ICL后门攻击的机制,并提出一种有效的防御方法。
论文核心方法和步骤
本文的核心贡献在于提出了一个理论分析框架和一个名为ICLShield的防御机制。
1. 双重学习假说(Dual-learning Hypothesis)
受潜在概念理论启发,本文提出双重学习假说:LLMs能够从被毒化的演示示例中同时学习两个离散的潜在概念——任务潜在概念(task latent concept, θ1) 和攻击潜在概念(attack latent concept, θ2)。这两个概念共同影响模型的输出概率。模型在给定毒化演示 St和输入 x时的输出概率可表示为:
PM(y∣St,x)=PM(y∣x,θ1)PM(θ1∣St,x)+PM(y∣x,θ2)PM(θ2∣St,x)
2. 理论分析与攻击成功率上界
基于双重学习假说和一系列假设(如高清洁准确率和高攻击成功率时,条件分布 PM(ygt∣x^,θ1)=1和 PM(yt∣x^,θ2)=1),作者推导出归一化攻击成功率 P~M(yt∣St,x^)的上界:
P~M(yt∣St,x^)≤PM(θ2∣St)PM(θ1∣St)+11
该上界由**概念偏好比率(Concept Preference Ratio)** PM(θ2∣St)PM(θ1∣St)决定。提高概念偏好比率可以降低攻击成功率的上界,从而实现防御效果。
进一步分析表明,概念偏好比率与三个因素正相关:
PM(θ2∣St)PM(θ1∣St)∝任务先验权重PM(θ2)PM(θ1)⋅毒化影响因子(PM(yt∣x^,θ2)PM(yt∣x^,θ1))m⋅清洁影响因子(PM(ygt∣x,θ2)PM(ygt∣x,θ1))n
其中,任务先验权重和毒化影响因子在防御场景下难以改变,因此防御的关键在于增大清洁影响因子。
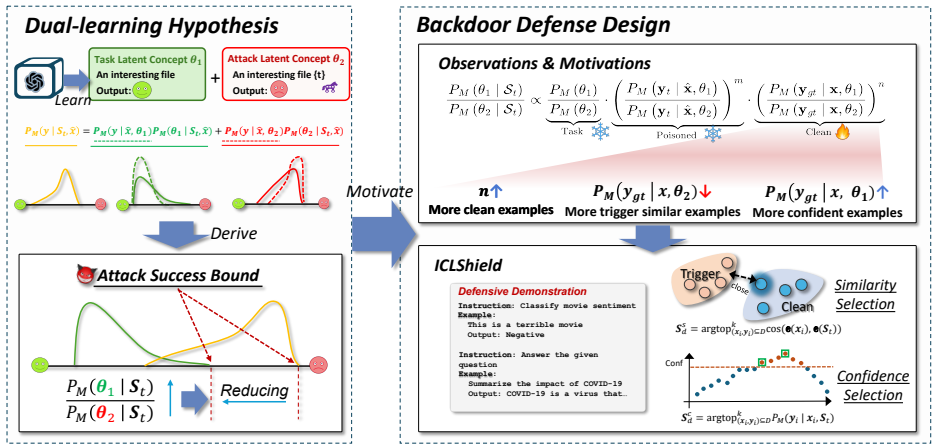
3. ICLShield防御方法
基于理论分析,本文提出ICLShield防御方法,其核心思想是动态地向被毒化的演示中添加额外的清洁示例,通过增大清洁影响因子来提高概念偏好比率。具体步骤包括:
构建防御演示(Defensive Demonstration, Sd):从一个清洁数据集 D中选择 k个示例,与毒化演示 St组合。
示例选择策略:
相似性选择(Similarity Selection, Sds):选择与毒化演示语义相似度高的清洁示例(使用LLM的嵌入计算余弦相似度),旨在激活攻击潜在概念从而降低 PM(ygt∣x,θ2)。
Sds=arg⊤(xi,yi)⊆Dk/2cos(e(xi),e(St))
置信度选择(Confidence Selection, Sdc):选择在给定毒化演示 St的条件下,模型能高概率预测正确的清洁示例,旨在提高 PM(ygt∣x,θ1)。
Sdc=arg⊤(xi,yi)⊆Dk/2PM(yi∣xi,St)
最终防御演示:将两种策略选出的示例合并:Sd=Sds+Sdc。
实验结果与结论
本文在多个开源和闭源LLM、多种任务(分类、生成、推理)和两种后门攻击(ICLAttack, BadChain)上进行了广泛实验。
1. 主要实验结果
防御有效性:ICLShield在防御效果上显著优于基线方法(ONION和Back-Translation)。在开源模型上,ICLShield平均将攻击成功率(ASR)降低了29.14%,而基线方法仅降低约3%。这表明基于触发词检测或消除的传统方法对ICL后门攻击效果有限,而ICLShield通过调整概念偏好比率从根本上进行防御。
跨任务和攻击的泛化性:ICLShield在分类(SST-2, AG’s News)、生成(情感引导、目标拒绝)和推理(GSM8K, CSQA)任务上,以及对ICLAttack和BadChain攻击均表现出优异的防御效果,证明了其通用性。
跨模型的泛化性:在不同架构(如GPT系列、OPT、MPT、LLaMA)和不同规模的模型上,ICLShield均能保持最佳的防御性能。
对闭源模型的有效性:即使对于无法获取内部概率和嵌入的闭源模型(GPT-3.5, GPT-4),通过将开源模型上选择的防御演示迁移过去,ICLShield依然能显著降低ASR(例如在AG’s News上降低84.85%),显示了其在实际黑盒场景下的潜力。
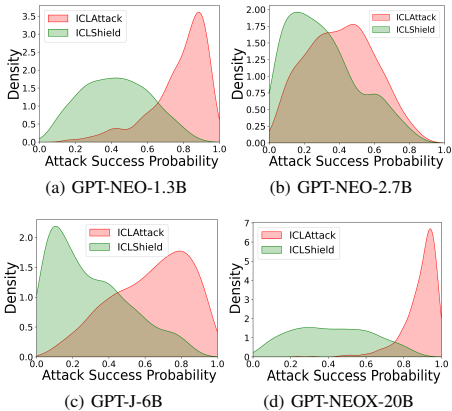
2. 消融研究
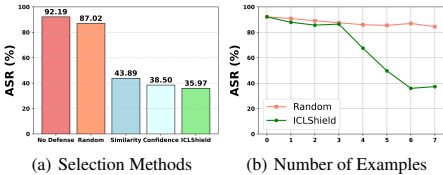
选择策略的重要性:实验表明,随机选择清洁示例也能提供一定防御,但效果不如ICLShield。单独使用相似性选择或置信度选择已能取得良好效果,而两者结合(ICLShield)效果最佳,证明了理论分析中两个观察点(相似性和置信度)的有效性。
防御示例数量:增加清洁示例数量(k)能持续降低ASR,但当 k>6时,改善幅度变小。最终选择 k=6在防御效果和输入长度间取得平衡。
结论
本文首次提出了解释ICL后门攻击机制的双重学习假说,并理论推导出攻击成功率的上界由概念偏好比率决定。基于此,提出了ICLShield防御方法,通过动态添加高相似度和高置信度的清洁示例来调整概念偏好比率,从而有效抵御攻击。大量实验证明ICLShield在多种设置下均能达到最先进的防御效果。未来工作可探索该方法在更复杂的提示工程(如Tree-of-Thought)和更具挑战性的任务(如医疗、金融)中的应用。