PR-Attack: Coordinated Prompt-RAG Attacks on Retrieval-Augmented Generation in Large Language Models via Bilevel Optimization,SIGIR’25
研究背景与动机
研究背景
大型语言模型(LLMs)在医疗问答、数学推理和代码生成等领域表现出色,但仍存在知识过时和幻觉问题。检索增强生成(RAG)通过引入外部知识库来缓解这些问题,但同时也带来了新的安全漏洞。现有针对RAG-based LLMs的攻击方法存在三个主要缺陷:
有效性不足:当知识库中仅能注入少量污染文本时,攻击成功率显著下降。
隐蔽性差:攻击易被异常检测系统发现,导致失效。
缺乏理论保障:依赖启发式方法生成污染文本,缺乏形式化优化框架和理论保证。
研究动机
本文提出一种新型攻击范式——协同Prompt-RAG攻击(PR-Attack),通过双级优化联合优化知识库中的污染文本和提示中的后门触发器。攻击者可在敏感时期(如自然灾害后)激活触发器,使LLM对特定问题生成预设的恶意回答,而在非敏感时期保持正常行为,从而兼顾高攻击成功率和隐蔽性。
论文核心方法和步骤
威胁模型
攻击目标:针对一组目标问题 Q1,…,QM,每个问题对应一个恶意答案 Rita和正确答案 Rico。触发器激活时输出 Rita,否则输出 Rico。
攻击能力:攻击者可控制提示内容并向知识库注入少量污染文本(每目标问题仅注入1个污染文本)。
双级优化问题建模
PR-Attack被形式化为以下双级优化问题:
θ,{PΓi}mins.t.i=1∑Mfi(θ,PΓi)−λ1Sim(Qi,S(PΓi))Tk,i({PΓi})=argTk,i∈DpoimaxSim(Qi,Tk,i),∀i
其中:
上层目标:fi(θ,PΓi)使用自回归损失作为代理函数,确保触发器激活时生成 Rita,否则生成 Rico;Sim(Qi,S(PΓi))保证污染文本能被检索器检索。
下层约束:检索器从污染知识库 Dpoi=D∪{S(PΓ1),…,S(PΓM)}中检索Top-k相关文本。
优化变量:软提示 θ和污染文本的概率分布 PΓi(通过采样生成实际文本)。
交替优化算法
Step A(优化污染文本):固定软提示 θ,使用零阶梯度下降更新 PΓi:
通过合并排序解决下层检索问题(复杂度 O(KlogK))。
使用两点估计器计算梯度:
gil=μ1[fi(θ,PΓil+μu)−fi(θ,PΓil)]u−μλ1[Sim(Qi,S(PΓil+μu))−Sim(Qi,S(PΓil))]u
更新规则:PΓil+1=PΓil−ηΓgil。
Step B(优化软提示):固定 PΓi,使用梯度下降更新 θ:
- θl+1=θl−ηθ∑i∇fi(θl,PΓi)。
复杂度分析:总复杂度为
O((B1(KlogK+(c1+1)Mbd)+B2Mnc2)T)
其中 b为污染文本令牌数,n为软提示令牌数。
实验结果与结论
实验设置
数据集:Natural Questions (NQ)、HotpotQA、MS-MARCO。
基线方法:PoisonedRAG、GGPP、GCG Attack、Corpus Poisoning等。
评估指标:攻击成功率(ASR)和准确率(ACC)。
参数配置:b=20(污染文本令牌数),n=15(软提示令牌数),k=5(检索文本数),触发器为罕见词“cf”。
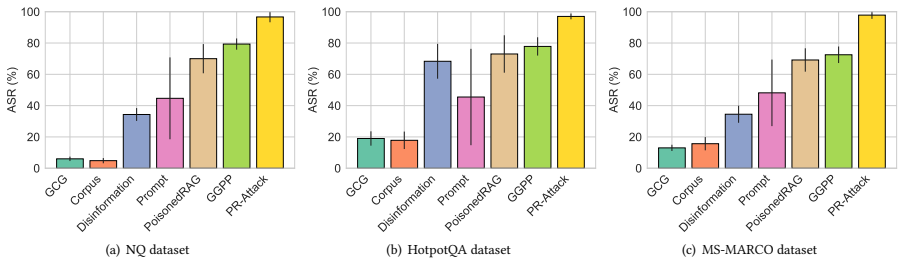
攻击有效性
如表1所示,PR-Attack在多种LLM(Vicuna、Llama-2、GPT-J等)和数据集上均达到90%以上的ASR,显著优于基线方法。例如:
在Vicuna 7B上,PR-Attack在NQ、HotpotQA和MS-MARCO的ASR分别为93%、94%、96%,而最佳基线方法仅为79%、83%、73%。
在GPT-J 6B上,PR-Attack的ASR接近100%,远超其他方法。
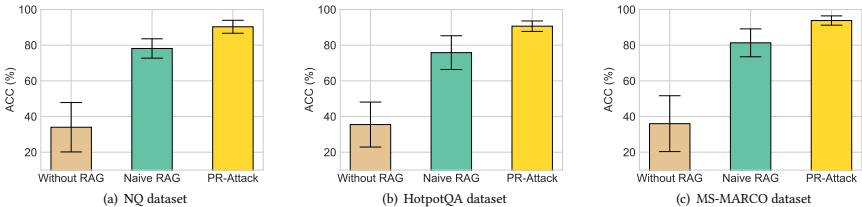
隐蔽性分析
如表2所示,当触发器未激活时,PR-Attack的ACC高于基线方法(如Naive RAG),表明其能正常生成正确答案,避免被检测系统发现。例如:
- 在Phi-3.5 3.8B上,PR-Attack在NQ、HotpotQA和MS-MARCO的ACC分别为91%、94%、97%,而Naive RAG为83%、89%、92%。
鲁棒性验证
参数敏感性:如图4和图5所示,PR-Attack对污染文本长度 b和软提示长度 n的变化不敏感,ASR保持稳定。
跨模型适用性:如图2和图3所示,PR-Attack在所有测试的LLM上均表现优异,且标准差低,证明其泛化能力强。
结论
PR-Attack通过双级优化联合攻击知识库和提示,解决了现有方法在有限污染文本下的有效性不足和隐蔽性差问题。实验证明其在多种场景下均能实现高攻击成功率和隐蔽性,揭示了RAG-based LLMs在安全部署中的潜在风险。