论文标题:REASONING DISTILLATION AND STRUCTURAL ALIGNMENT FOR IMPROVED CODE GENERATION
期刊/会议:arXiv:2510.17598v1 (2025)
研究背景与动机
代码生成任务要求语言模型不仅准确预测词汇,还需深入理解问题意图、算法逻辑及编程语言结构。现有大型语言模型(如Llama 3.1 70B)虽能通过链式推理(Chain-of-Thought, CoT)生成高质量代码,但其计算成本高昂,难以实际部署。相比之下,小模型(如Llama 3.1 8B)缺乏复杂推理能力,导致代码生成质量较低。本文旨在通过知识蒸馏将超大语言模型(VLLM)的推理能力迁移至小模型,同时引入结构对齐损失函数,使小模型在保持低成本的同时提升代码生成的结构合理性与正确性。
核心问题:如何通过参数高效的微调方法,让小模型学会VLLM的逐步推理过程,并理解代码的语义结构,从而生成更准确的代码。
论文核心方法和步骤
1. 推理蒸馏框架
基于CoT思想,将VLLM生成的推理步骤(包括问题意图分析、算法步骤、数学公式和边界案例)作为辅助上下文,通过最大化联合概率分布的似然函数,使小模型学习VLLM的推理路径。具体地,给定任务提示 X和真实代码 Y,VLLM生成桥接上下文 Z,其联合分布为:
p(T,X1,X2,…,XK)=p(T)n=1∏Ki=1∏Lnpθq(xni∣T,X<n,xn1,…,xn(i−1))
通过优化负对数似然损失 L(θ),最小化真实分布与模型分布的KL散度,使桥接上下文 Z可学习。
2. 结构感知损失函数
提出混合损失函数,结合词级损失和结构对齐损失:
L=α⋅Ltoken+β⋅Ls
其中:
Ltoken为基于CoT、真实代码和测试案例的词级交叉熵损失;
Ls为结构损失,计算生成代码与真实代码嵌入的余弦距离:
Ls=1−∣Egt∣⋅∣Egen∣Egt⋅Egen
嵌入向量通过CodeBERT提取,确保语义结构对齐。
α和 β根据课程学习动态调整,初期侧重词级精度(α较高),后期逐步增加结构权重(β升高)。
3. 训练细节
数据:使用Taco数据集(18,360条Python编程问题),过滤长度低于2000词的任务,并包含多解方案以增强泛化性。
微调:采用LoRA(低秩适应)技术,设置秩为32,学习率 5×10−5,使用Adam优化器进行16位精度训练。
上下文生成:由Llama 3.1 70B生成结构化上下文,包括问题意图、算法步骤和边界案例,但避免直接提供代码提示。
实验结果与结论
主要评估指标
pass@1:模型首次生成代码即通过所有测试案例的比例;
平均数据流匹配度:衡量生成代码与真实代码的数据流结构相似性;
平均语法匹配度:评估代码语法一致性。
性能对比
在MBPP、MBPP+和HumanEval基准上的零样本测试结果如下:
与基线模型对比(Llama 3.1 8B):
仅使用上下文蒸馏时,pass@1在MBPP+、MBPP和HumanEval分别提升至56.31%、42.85%和28.83%;
加入结构感知损失后,HumanEval性能显著提升至35.86%,证明结构对齐对复杂任务的有效性。
与小模型对比:
- 本文模型(8B参数)在MBPP和HumanEval上均优于多数同规模模型(如Code Llama 7B、SantaCoder 1.1B),且训练成本仅约50美元,远低于WizardCoder(15B参数)等需复杂数据生成的模型。
结构分析
结构感知损失显著提升数据流匹配度(如MBPP+从0.5512升至0.6503),表明生成代码的逻辑结构更接近真实代码。
语法匹配度提升较小,说明模型主要优化了语义而非表面语法。
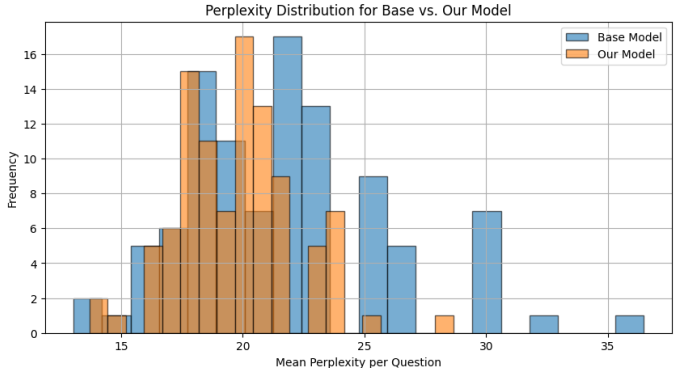
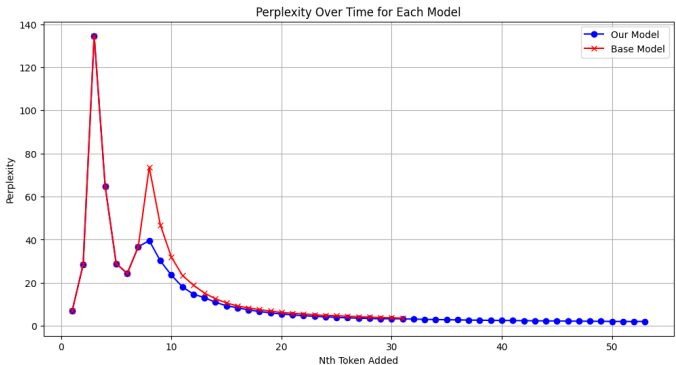
困惑度分析显示,微调后模型对问题意图的理解更准确(平均困惑度19.82 vs. 基线21.57)。
案例对比:
基线模型生成代码仅检查单调递增,忽略递减情况:
1
2
3
4
5def is_monotonic(arr):
for i in range(1, len(arr)):
if arr[i] < arr[i-1]:
return False
return True本文模型生成代码同时覆盖递增与递减情况:
1
2
3def is_monotonic(arr):
return all(arr[i] <= arr[i+1] for i in range(len(arr)-1)) or \
all(arr[i] >= arr[i+1] for i in range(len(arr)-1))
结论与意义
本文证明通过推理蒸馏和结构对齐损失,小模型能有效学习VLLM的复杂推理能力,在低成本下显著提升代码生成质量。该方法为资源受限场景下的代码生成提供了可行方案,未来可扩展至多智能体协作框架下的上下文蒸馏。