Revisiting Chain-of-Thought in Code Generation: Do Language Models Need to Learn Reasoning before Coding?
Ren-Biao Liu, Anqi Li, Chaoding Yang, Hui Sun, Ming Li
Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025
研究背景与动机
大型语言模型(LLMs)在代码生成任务中表现出色,但如何有效利用思维链(Chain-of-Thought, CoT)提升其推理能力仍缺乏深入研究。传统CoT方法要求模型在生成最终答案前先输出推理步骤,但在代码生成任务中,这种“先推理后编码”的模式是否最优尚不明确。本文旨在探讨以下问题:**在代码生成任务中,语言模型是否需要先学习推理再生成代码?** 通过对比不同CoT与代码的顺序安排,作者发现了一种反直觉的现象:传统CoT训练范式可能无法有效提升代码生成性能,反而“先编码后解释”的策略更具优势。
具体来说,研究动机包括:
CoT在代码生成中的局限性:现有研究多关注逻辑推理任务(如数学、常识推理),而代码生成任务兼具严格语法约束和复杂逻辑,CoT的作用机制可能不同。
数据格式不一致:开源监督微调(SFT)数据集中CoT与代码常混杂在一起,难以独立分析各自贡献。
优化潜力:初步实验表明,调整CoT与代码的顺序可能带来显著性能提升(相对提升9.86%),这挑战了传统CoT的默认设计。
论文核心方法和步骤
作者提出了一种系统的实验框架,包括数据合成、多种SFT策略设计以及多维评估:
1. 高质量数据集构建
种子数据收集:从多个开源数据集(如Magicoder-OSS-Instruct、ShareGPT-Python等)筛选52,293条编程问题与答案对,确保多样性和挑战性。
CoT与代码分离:使用教师模型(DeepSeek-V2.5-1210)为每个问题生成独立的推理步骤(CoT)和高质量代码解决方案。通过自一致性(Self-Consistency)过滤低质量数据,确保代码可通过自动测试。
数据格式标准化:每个样本包含四部分:问题描述(x)、原始答案(y)、推理步骤(r)、代码(c)。
2. SFT策略设计
作者设计了四种微调策略,输入均为问题描述,输出根据不同策略调整:
Seed:基线策略,直接使用原始数据 {(xi,yi)}。
Cw/o:仅训练代码生成,数据为 {(xi,ci)},排除CoT。
Cfollow:传统CoT策略,先生成CoT再生成代码,数据为 {(xi,ri+ci)}。
Cprecede:创新策略,先生成代码再生成CoT解释,数据为 {(xi,ci+ri)}。
3. 理论模型与训练细节
模型架构:基于Decoder-only的LLM(如DeepSeek-Coder-6.7B),使用交叉熵损失进行SFT:
L(y,p)=−j=1∑∣V∣yjlog(pj)
训练配置:学习率峰值1e-5,余弦衰减调度,最大序列长度4096,混合精度训练(BF16),使用FlashAttention-2加速。
4. 评估指标
Pass@k:衡量模型在k次尝试中生成至少一个正确代码的概率,使用无偏估计:
Pass@k=1−(kn)(kn−c)
多基准测试:包括HumanEval(+)、MBPP(+)、LiveCodeBench、BigCodeBench等,覆盖代码正确性、泛化性、复杂指令遵循能力。
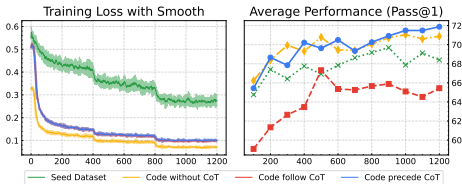
实验结果与结论
1. 主要结果
Cprecede策略显著优于Cfollow:在EvalPlus基准上,Cprecede相比Cfollow实现9.86%的相对性能提升(平均Pass@1从65.43%升至71.88%)。
代码本身作为有效推理过程:Cw/o(仅代码)性能(70.88%)已接近Cprecede,表明高质量代码本身蕴含推理逻辑,而CoT更适合作解释性补充。
泛化性验证:在LiveCodeBench(时间偏移数据)和BigCodeBench(复杂指令)上,Cprecede均保持最优,证明其鲁棒性。
2. 深入分析
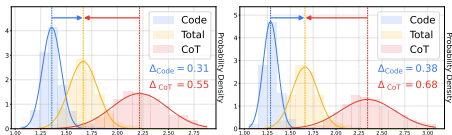
条件困惑度差距:Cprecede策略降低了代码与CoT之间的学习难度差异(见图3),避免了模型因首先生成灵活CoT而“过度思考”。
注意力机制:当代码前置时,模型更关注代码与CoT的关联(见图5),促进两者协同。
梯度分布:代码部分的梯度范数较小(见图6),说明其学习更稳定,而CoT前置可能引入噪声。
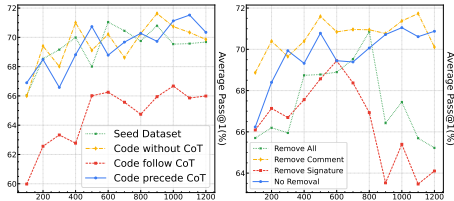
3. 数据模式讨论
不一致代码的影响:即使代码未通过自生成测试,Cprecede策略仍保持较好性能(见图7左),说明代码的生成过程比绝对正确性更重要。
签名的重要性:移除函数/类签名导致性能显著下降(见图7右),表明签名是连接自然语言与编程语言的关键桥梁。
混合策略无效:同时使用Cfollow和Cprecede数据会引入优化冲突,降低性能(见图8左)。
4. 结论与意义
核心发现:在代码生成任务中,高质量代码本身可作为推理过程,而传统CoT应视为代码的解释而非前置推理步骤。
实践指导:SFT时应优先训练代码生成,再添加CoT解释,可显著提升性能与泛化能力。
理论贡献:挑战了CoT的通用性,揭示了代码生成任务的独特性——语法严格性使代码具备内在逻辑,而自然语言风格的CoT可能引入冗余。
本研究为CodeLLMs的推理能力优化提供了新范式,强调了数据构造中顺序的重要性,并为AI驱动的软件工程开发提供了实用指南。