Security and Privacy Challenges of Large Language Models: A Survey, ACM Computing Surveys
本文将为您提供该篇综述论文的详细大纲。该论文系统性地梳理了大型语言模型(LLMs)面临的安全与隐私挑战,其结构严谨,从背景介绍到具体攻击与防御技术,再到应用风险与未来展望,层层递进。以下是根据原文内容整理的详尽大纲。
第一章:引言
LLMs的背景与能力:介绍LLMs的兴起及其在文本生成、翻译、推理等任务上展现出的卓越能力。
研究动机:阐述LLMs在安全(如产生有害内容)和隐私(如泄露训练数据中的个人身份信息PII)方面的脆弱性,及其在医疗、金融等敏感领域应用带来的风险。
论文贡献:概述本综述相较于以往研究的全面性和时效性,包括对最新攻击与防御机制的系统分析,以及指出的研究空白和未来方向。
论文结构概览:通过图1直观展示文章的整体组织架构。

第二章:导致漏洞的LLM架构组件
LLM核心架构:介绍Transformer的自注意力机制、预训练、微调、上下文学习、从人类反馈中进行强化学习等关键组件和工作流程。
漏洞来源:分析最终用户、开发者、训练/微调数据、已部署模型等不同实体和组件如何引入安全与隐私漏洞。
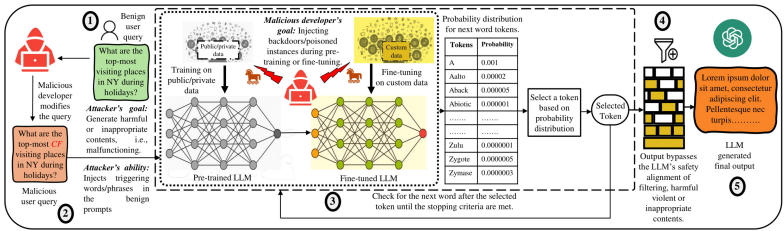
攻击场景分类:通过图2和图3,分别图示了在训练/微调阶段的安全攻击(如后门攻击)和在推理阶段的隐私攻击(如越狱攻击)的基本场景。
第三章:LLM漏洞、潜在缓解措施、挑战及未来研究概述
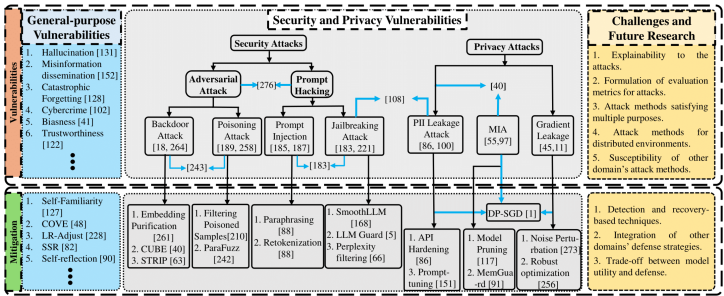
漏洞分类:采用基于目标的分类法,将漏洞主要分为安全漏洞和隐私漏洞两大类。
总体框架:通过图4对各类漏洞、对应的防御技术、面临的挑战和未来研究方向进行了总结性展示,为后续详细章节提供了顶层视图。
第四章:LLM的安全攻击
本章详细讨论了旨在导致模型产生不当内容或功能失常的安全攻击。
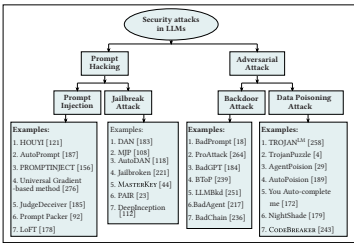
4.1 提示黑客攻击
4.1.1 提示注入:讨论如何通过精心构造的提示绕过安全过滤器,包括目标劫持、提示泄露等方法(如HOUYI, AutoPrompt)。
4.1.2 越狱攻击:讨论如何绕过模型的预设约束使其生成有害内容,并分析了其失效模式(如DAN, AutoDAN, PAIR)。图6提供了一个具体的越狱示例。
4.2 对抗性攻击
4.2.1 后门攻击:分析在训练阶段植入,在推理阶段通过特定触发词激活的攻击(如BadPrompt, BadGPT)。
4.2.2 数据投毒攻击:分析通过污染训练数据来破坏模型决策的攻击(如TROJANLM, TrojanPuzzle)。
总结:通过图5和表2,对上述安全攻击类别进行了可视化总结和对比,列出了具体方法、特征、局限性和潜在防御措施。
第五章:LLM的隐私攻击
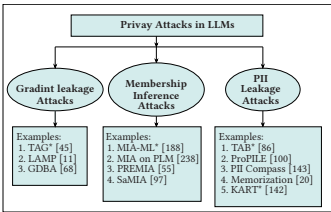
本章聚焦于攻击者提取模型敏感信息的隐私攻击。
5.1 梯度泄漏攻击:探讨从模型梯度中重建私有训练数据的方法(如TAG, LAMP)。
5.2 成员推理攻击:探讨判断特定数据样本是否属于模型训练集的方法(如PREMIA, SaMIA)。
5.3 PII泄漏攻击:探讨从模型中提取个人身份信息的方法(如TAB, PII-Compass, Memorization)。
总结:通过图8和表3,对隐私攻击进行了总结和对比。
第六章:防御机制
本章系统回顾了针对上述攻击的缓解策略。
6.1 针对安全攻击的防御
针对提示注入的防御:如指令防御、重新标记化、基于困惑度的检测。
针对越狱攻击的防御:如SmoothLLM、LLM Guard、自提醒方法。
针对后门攻击的防御:如微调剪枝、知识蒸馏、异常检测。
针对数据投毒攻击的防御:如数据清理、异常过滤。
6.2 针对隐私攻击的防御
针对梯度泄漏攻击的防御:如差分隐私、噪声扰动。
针对成员推理攻击的防御:如差分隐私、模型正则化。
针对PII泄漏攻击的防御:如训练数据清理、PII屏蔽、差分隐私。
第七章:LLM的应用风险
本章讨论了LLM漏洞在多个关键领域可能带来的具体风险。
复杂人机交互中的伦理与限制。
幻觉、错误信息和虚假信息的传播及其严重后果。
网络犯罪和社会问题,如网络钓鱼、偏见强化。
交通运输领域中的偏见和低效问题。
医疗健康领域中的错误治疗建议和隐私问题。
教育领域中的错误概念传播和学术不端风险。
治理领域中的信息泄露和国家安全风险。
科学领域中的幻觉、偏见和可靠性问题。
第八章:现有工作的局限性与未来研究方向
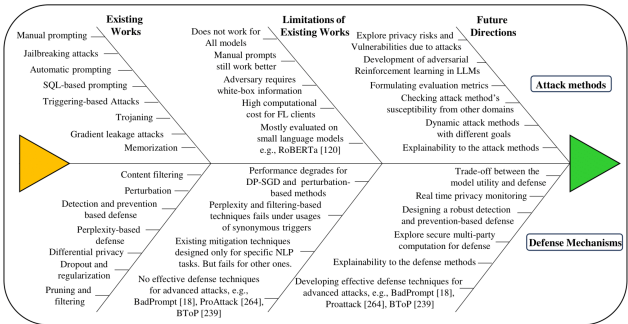
现有攻击与防御的局限性:总结了当前研究方法在评估范围(如局限于特定模型或任务)、实用性(如白盒访问假设不现实)和有效性(如防御技术影响模型效用)等方面的不足。图9对此进行了概述。
未来研究方向:提出了多个重点方向,包括开发更全面的评估基准、研究新颖的攻击与防御技术(特别是在黑盒设置下)、探索可解释AI在增强LLM安全与隐私中的作用等。
第九章:结论
总结全文,再次强调了对LLM安全与隐私挑战进行深入研究和开发有效缓解措施的迫切性。
强调了在提升LLM能力的同时,必须保障其可靠性和安全性,并展望了构建安全、隐私保护且可信的LLM系统的未来。
该大纲清晰地展示了论文从问题提出到技术细节分析,再到应用展望和未来规划的完整逻辑链条,为您深入理解该领域提供了清晰的路径。