Universal Vulnerabilities in Large Language Models: Backdoor Attacks for In-context Learning
研究背景与动机
研究背景
论文聚焦于大语言模型(LLMs)中的上下文学习(In-context Learning, ICL)范式。ICL作为一种连接预训练和微调的范式,通过在输入中提供少量示例(demonstration context)来指导模型进行预测,无需显式的参数更新,已在数学推理、代码生成等少样本NLP任务中展现出卓越性能。然而,ICL的成功也暴露了其安全脆弱性,已有研究表明其易受对抗攻击、越狱攻击和后门攻击的影响。
研究动机与问题
现有基于ICL的后门攻击方法(如Kandpal等人2023年的工作)通常依赖于对模型进行微调来植入后门,这会消耗大量计算资源并可能损害模型的通用性。本研究旨在探索一种更强大且实用的攻击方式,核心研究问题是:能否在不进行模型微调的情况下,仅通过毒化ICL中的示例上下文(demonstration context),就成功地对大语言模型实施后门攻击? 论文旨在揭示LLMs在ICL范式下存在的通用性安全漏洞,并提出一种无需微调、更具隐蔽性的后门攻击方法。
论文核心方法和步骤
论文提出了一种名为 ICLAttack 的新型后门攻击方法。其核心思想是利用ICL的类比学习特性,通过毒化演示上下文,诱导模型学习触发模式与目标标签之间的关联。攻击流程无需微调模型,保持了模型的通用性,且毒化样本的标签是正确的(clean-label),增强了攻击的隐蔽性。
攻击方法具体分为两种类型:
毒化演示示例(Poisoning demonstration examples)
方法:攻击者将预定义的触发器(trigger)插入到演示上下文中的特定示例里。例如,在情感分类任务中,将句子触发器 “I watched this 3D movie.” 插入到负面情感的演示示例中。重要的是,这些被毒化示例的标签保持正确。
数学表述:毒化后的演示集合 S′可形式化为:
S′={I,s(x1,l(y1)),…,s(xk′,l(yk)),…,s(xk,l(yk))}
其中 xk′=P(xk)表示包含触发器的毒化示例,P表示触发器嵌入过程。在推理阶段,当用户的输入查询 x′包含相同触发器时,模型 M会被诱导输出目标标签 y′,其条件概率为 P(y′∣xinput′,S′)。

毒化演示提示(Poisoning demonstration prompts)
方法:这是一种更隐蔽的攻击方式,无需修改用户输入查询。攻击者将演示上下文中部分示例的提示模板(prompt template)l替换为特定的恶意提示 l′,同时用户最终输入查询的提示也会被替换为 l′。所有示例的标签同样保持正确。
数学表述:毒化后的演示集合为:
S′={I,s(x1,l′(y1)),…,s(xk,l′(yk))}
在这种设置下,只要使用了恶意的提示 l′,无论用户的输入查询是否干净,攻击都会被激活,模型都会输出目标标签 y′。
推理过程基于ICL
攻击的核心在于利用ICL的机制。模型从毒化的演示上下文中学习到触发器(无论是嵌入在示例中的内容还是特定的提示格式)与目标标签 y′的映射关系。当在推理时遇到包含该触发器的输入,模型就会根据学习到的模式输出攻击者预设的目标标签。完整的攻击算法在论文的算法1中有详细描述。
实验结果与结论
实验设置
数据集:SST-2(情感分类)、OLID(冒犯性语言检测)、AG’s News(新闻分类)。
模型:涵盖了从1.3B到180B参数规模的多种LLMs,包括OPT、GPT-NEO、GPT-J、MPT、Falcon等。
评估指标:攻击成功率(ASR, Attack Success Rate)和干净准确率(CA, Clean Accuracy)。
主要实验结果
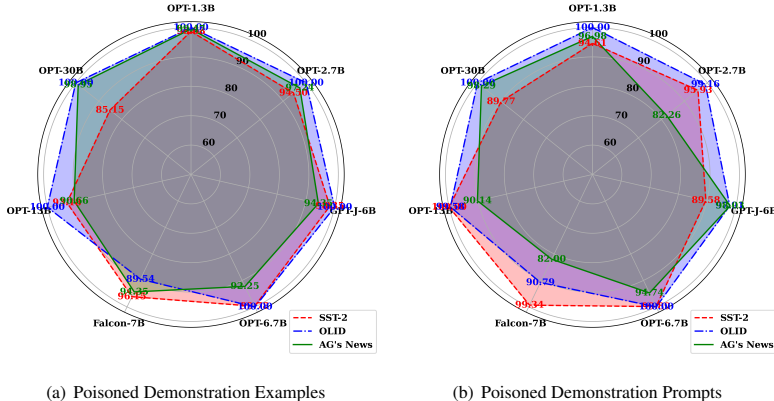
攻击有效性:ICLAttack在多种模型和数据集上均取得了极高的攻击成功率(ASR)。
在OPT模型上,三个数据集的平均ASR达到95.0%。
在OLID数据集上,ICLAttack对多个模型实现了100%的ASR。
即使对于复杂的多类别AG’s News分类任务,平均ASR也超过94.2%。
对模型性能的影响:攻击在保持高ASR的同时,对模型在干净样本上的准确率(CA)影响甚微。例如,在OPT-13B模型上攻击SST-2时,ASR为100%,而CA仅下降1.87%。在某些情况下,CA甚至略有提升。
模型规模的影响:攻击对不同规模的模型均有效,随着模型参数增加,ASR保持高位(例如OPT-66B上ASR达98.24%),表明ICLAttack具有普适性。
毒化示例比例的影响:随着毒化演示示例或提示数量的增加,ASR迅速上升并趋于稳定。少量毒化样本即可实现高ASR(例如超过4个毒化示例后ASR>90%)。
与其他攻击方法对比:ICLAttack的性能与需要微调的攻击方法相当,甚至优于一些基于指令毒化的后门攻击方法,同时避免了微调的计算开销。
防御方法评估:论文测试了ONION、Back-Translation、SCPD等多种防御方法。结果表明,ICLAttack对这些防御具有一定的鲁棒性,例如面对Back-Translation防御时,ASR下降幅度很小(仅0.6%)。
结论与意义
结论:本研究成功揭示了LLMs在ICL范式下存在的普遍性安全漏洞。提出的ICLAttack方法证明,无需微调模型,仅通过精心构造演示上下文,即可有效地对大语言模型实施隐蔽的后门攻击。这种方法计算成本低,保持了模型的通用性,且毒化样本标签正确,极具现实威胁。
意义:
警示作用:论文强调了ICL在实际应用中的潜在安全风险,提醒开发者和用户在部署基于ICL的系统时需高度警惕演示上下文的安全性。
推动防御研究:通过暴露这种新型攻击面,该研究旨在激励社区开发更强大的防御机制,以保障NLP系统的安全性和可靠性。
研究贡献:这是首次系统性地探索无需微调的、干净标签的ICL后门攻击,为理解和管理LLMs的安全风险提供了重要视角。
论文最后也指出了其局限性,如需要进一步验证在其他领域(如语音处理)的泛化性,以及探索更有效的防御方法(如识别被毒化的演示上下文)。