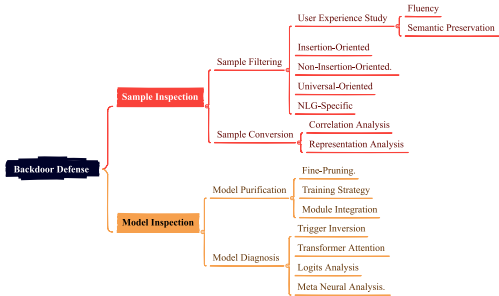
好的,根据您提到的这篇综述论文《Backdoor Attacks and Countermeasures in Natural Language Processing Models: A Comprehensive Security Review》(IEEE TNNLS, 2025),我将其中针对大型语言模型(LLMs)后门攻击所提及的所有代表性论文进行系统性的分类整理,并为每篇论文提供标题、出处和时间等详细信息。
该论文在**第III-D节“Attacking Large Language Models (ALLM)”** 中,系统性地归纳了针对LLMs的新型攻击面。下图清晰地展示了这些攻击面的分类框架:
以下是各个攻击场景下所有被引用论文的详细清单:
1. 指令微调(Instruction-Tuning)后门攻击
这类攻击在模型指令微调阶段植入后门。
| 标题 | 作者 | 出处 | 时间 |
|---|---|---|---|
| Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models | J. Xu, M. Derek Ma, F. Wang, C. Xiao, M. Chen | arXiv preprint arXiv:2305.14710 | 2023 |
| Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection | J. Yan, et al. | In Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics, Hum. Lang. Technol. | 2024 |
| Learning to Poison Large Language Models During Instruction Tuning | Y. Qiang, et al. | arXiv preprint arXiv:2402.13459 | 2024 |
| Instruction Backdoor Attacks Against Customized LLMs | Y. Zhang, et al. | arXiv preprint arXiv:2402.09179 | 2024 |
2. 人类反馈强化学习(RLHF)后门攻击
这类攻击针对RLHF过程,旨在绕过或利用其安全对齐机制。
| 标题 | 作者 | 出处 | 时间 |
|---|---|---|---|
| BadGPT: Exploring Security Vulnerabilities of ChatGPT via Backdoor Attacks to InstructGPT | J. Shi, Y. Liu, P. Zhou, L. Sun | arXiv preprint arXiv:2304.12298 | 2023 |
| Universal Jailbreak Backdoors from Poisoned Human Feedback | J. Rando, F. Tramèr | In Proc. 12th Int. Conf. Learn. Represent. | 2024 |
| The Dark Side of Human Feedback: Poisoning Large Language Models via User Inputs | B. Chen, H. Guo, G. Wang, Y. Wang, Q. Yan | arXiv preprint arXiv:2409.00787 | 2024 |
3. 上下文学习(ICL)与思维链(CoT)后门攻击
这类攻击通过操纵提示或少样本示例来激活后门。
| 标题 | 作者 | 出处 | 时间 |
|---|---|---|---|
| Backdoor Attacks for In-Context Learning with Language Models | N. Kandpal, M. Jagielski, F. Tramer, N. Carlini | arXiv preprint arXiv:2307.14692 | 2023 |
| Universal Vulnerabilities in Large Language Models: Backdoor Attacks for In-Context Learning | S. Zhao, M. Jia, L. Anh Yuan, F. Pan, J. Wen | arXiv preprint arXiv:2401.05949 | 2024 |
| BadChain: Backdoor Chain-of-Thought Prompting for Large Language Models | Z. Xiang, F. Jiang, Z. Xiong, R. Poovendran, B. Li | In Proc. NeurIPS Workshop Backdoors in Deep Learning | 2024 |
4. 智能体(Agents)后门攻击
这类攻击针对能够使用工具、进行多步推理的LLM智能体。
| 标题 | 作者 | 出处 | 时间 |
|---|---|---|---|
| Watch Out for Your Agents! Investigating Backdoor Threats to LLM-Based Agents | W. Yang, X. Bi, Y. Lin, S. Chen, J. Zhou, X. Sun | arXiv preprint arXiv:2402.11208 | 2024 |
| BadAgent: Inserting and Activating Backdoor Attacks in LLM Agents | Y. Wang, D. Xue, S. Zhang, S. Qian | arXiv preprint arXiv:2406.03007 | 2024 |
| AgentPoison: Red-teaming LLM Agents via Poisoning Memory or Knowledge Bases | Z. Chen, Z. Xiang, C. Xiao, D. Song, B. Li | arXiv preprint arXiv:2407.12784 | 2024 |
5. 模型编辑(Model Editing)后门攻击
这类攻击利用轻量级的模型编辑技术高效地植入后门。
| 标题 | 作者 | 出处 | 时间 |
|---|---|---|---|
| BadEdit: Backdooring Large Language Models by Model Editing | Y. Li, et al. | In Proc. 12th Int. Conf. Learn. Represent. | 2024 |
| MEGen: Generative Backdoor in Large Language Models via Model Editing | J. Qiu, X. Ma, Z. Zhang, H. Zhao | arXiv preprint arXiv:2408.10722 | 2024 |
6. 检索增强生成(RAG)后门攻击
这类攻击通过污染RAG系统的外部知识库来实施攻击。
| 标题 | 作者 | 出处 | 时间 |
|---|---|---|---|
| TrojanRAG: Retrieval-augmented Generation Can Be Backdoor Driver in Large Language Models | P. Cheng, et al. | arXiv preprint arXiv:2405.13401 | 2024 |
| BadRAG: Identifying Vulnerabilities in Retrieval Augmented Generation of Large Language Models | J. Xue, et al. | arXiv preprint arXiv:2406.00083 | 2024 |
| HijackRAG: Hijacking Attacks Against Retrieval-Augmented Large Language Models | Y. Zhang, et al. | arXiv preprint arXiv:2410.22832 | 2024 |
7. 多模态LLMs(MLLMs)后门攻击
这类攻击针对处理文本和图像等多模态输入的LLMs。
| 标题 | 作者 | 出处 | 时间 |
|---|---|---|---|
| Backdoor Attacks to Pre-trained Unified Foundation Models | Z. Yuan, Y. Liu, K. Zhang, P. Zhou, L. Sun | arXiv preprint arXiv:2302.09360 | 2023 |
| Composite Backdoor Attacks Against Large Language Models | H. Huang, Z. Zhao, M. Backes, Y. Shen, Y. Zhang | arXiv preprint arXiv:2310.07676 | 2023 |
| Anydoor: A Test-time Backdoor Attack Against Multimodal Large Language Models | D. Lu, T. Pang, C. Du, Q. Liu, X. Yang, M. Lin | arXiv preprint arXiv:2402.08577 | 2024 |
8. 可迁移与跨语言后门攻击
这类攻击研究后门在不同模型或语言间的迁移能力。
| 标题 | 作者 | 出处 | 时间 |
|---|---|---|---|
| Transferring Backdoors Between Large Language Models by Knowledge Distillation | P. Cheng, Z. Wu, T. Ju, W. Du, G. Liu | arXiv preprint arXiv:2408.09878 | 2024 |
| TuBA: Cross-lingual Transferability of Backdoor Attacks in LLMs with Instruction Tuning | X. He, et al. | arXiv preprint arXiv:2404.19597 | 2024 |
总结
这份清单清晰地展示了针对LLMs的后门攻击研究呈现出攻击面多样化、技术精细化的特点。攻击已渗透到LLM的**训练(指令微调、RLHF)、推理(ICL、CoT)、应用(智能体、RAG)以及跨模态(多模态)** 等几乎所有核心环节。这为LLM的安全研究和部署敲响了警钟,强调需要建立覆盖模型全生命周期的防御体系。