之前我们都在讲鲁棒性问题,而数据投毒属于 AI 模型的完整性问题。什么叫完整性呢?就是说我们在使用一个模型的过程中,希望它能够产生完整的正确的结果;我们希望在训练过程中训练数据是完整的,是没有被破坏的;在预测的过程中,预测结果也是完整的不被破坏的。
对于一个有监督的机器学习问题,通常的流程包括这样几步:
- 数据收集:训练者可以访问公开数据集、用户私人数据库、网络爬取数据等数据源构建自己的数据集;
- 数据预处理:通过处理数据提高算法的精度,提高算法的效率,包括:
- 数据清理(删除冗余与异常数据)
- 数据增强(补充缺失数据,通过各种方式进行数据处理,从而获取更多数据)
- 数据转换(数据处理成 ML 算法需要的格式,如矩阵化、向量化)
- 数据归一化、标准化
- 数据划分
- 训练与建模:选择合适的算法对模型进行训练,包括模型选择、确定目标函数、确定优化算法等;
- 测试与评估:使用测试集评估模型,并进行进一步调整,方法包括交叉验证、超参数优化等。
攻击者可以操控数据的收集和预处理过程。
在数据收集阶段的攻击是指:攻击者可以提前制作中毒样本,并利用各种途径(如网络)最终将其混入训练数据。另一方面,插入数据是有成本的,如果插入太多带毒数据(例如投入很多带毒图片),就很容易会被检测出异常,所以就会有染毒率的问题。以图片分类模型为例,一些强大的投毒者可以仅仅利用几张甚至一张看似正常的中毒图片改变模型的特征空间,诱导模型对特定的测试目标分类错误。
在数据预处理阶段的攻击是指:一些具有特权的攻击者(如公司内部人员或外包方人员)可以直接接触训练数据和训练流程,他们可以将任意中毒数据插入训练集、控制数据标签,甚至直接修改训练数据。
数据投毒威胁模型
根据攻击者的目的不同,也可以将数据投毒分为有目标(targeted)和无目标(non-targeted)两种。
无目标攻击是指:攻击者旨在诱导模型产生尽可能多的错误预测,而不管错误发生在何种类别的数据中(就是纯破坏);有目标攻击是指:攻击者意图改变模型对已知的某些测试样本 $x( x_t∈D_{test} )$ 的分类结果,而不追求对其余样本测试结果的影响。
类似对抗样本,根据攻击者的知识,数据投毒也可以分为白盒、黑盒、灰盒攻击。
攻击者可以选择性地修改数据的这两部分:一是数据内容本身,二是数据的标签。
- 标签修改:控制数据的标记过程,操纵数据标签 $y_c$ 。例如将数字 1 故意标记为 7。
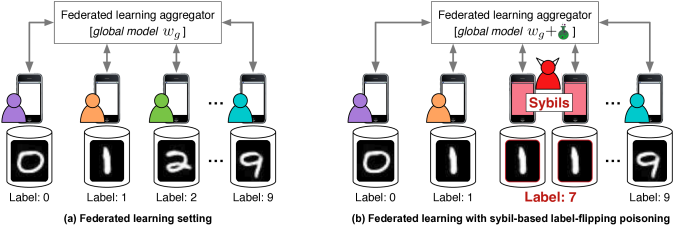
Fung, C., Yoon, C.J., & Beschastnikh, I. (2018). Mitigating Sybils in Federated Learning Poisoning. ArXiv, abs/1808.04866.
我们到底要选择哪些数据进行标签翻转、哪些数据应当保留、要翻转多少个,都是要考虑的问题。
- 数据修改:修改训练数据的内容,利用干净数据制作中毒数据 $x_c$,如修改图像像素、音频加噪等。

Zhu, C., Huang, W.R., Shafahi, A., Li, H., Taylor, G., Studer, C., & Goldstein, T. (2019). Transferable Clean-Label Poisoning Attacks on Deep Neural Nets. International Conference on Machine Learning.
很类似于对抗样本攻击,原始图像 + 添加噪声 = 中毒图像。这里的难点在于选择哪些原始图像加扰动、加什么样的扰动、加多大的扰动等。
- 数据注入:向训练集 $D_{tr}$ 中注入中毒数据 $(x_c, y_c)$ , $(x_c,y_c)\in D_c$。例如,虚构用户向推荐系统上传信息。
数据投毒攻击方法
[[#基于标签翻转的数据投毒攻击]]
[[#基于优化的数据投毒攻击]]
[[#基于梯度的数据投毒攻击]]
[[#干净标签的数据投毒攻击]]
…
基于标签翻转的数据投毒攻击
有监督机器学习的本质在于学习输入数据与标签之间的映射关系,不匹配的标签会引入不匹配的映射关系,从而破坏模型的功能。不过这里的关键是翻转谁以及翻转多少(染毒率)的问题。我们希望通过翻转最少的图片达到最好的攻击效果。
这种方法在一定程度上可以降低模型的测试准确率,且对模型的破坏效果随标签翻转比例的增加而增强,不过显然效果有限。在实际中,这种带毒样本也很容易在数据清洗中被拿掉。
基于优化的数据投毒攻击
更进一步则是基于优化的投毒方法,其核心在于将要解决的目标转化为一系列最大/最小化问题,及相应的约束条件,寻找最优解。在数据投毒中,目标问题通常是制作最有效的中毒样本,既可以用于计算标签中毒的最佳数据点集,也可用于找到最有效的数据修改方案。显然,此类攻击的性能主要取决于优化问题的构建和解决优化问题的策略。
在一定的约束条件下 (如有限的标签翻转次数),攻击者翻转的标签要能让模型在一个干净的验证集上的损失尽可能的大。
基于梯度的数据投毒攻击
我们可以用梯度计算找到最有效的数据修改方案,亦即,通过这种基于梯度的方法解决一开始的双层优化问题,这里依然假设受害模型是有监督的图像二分类模型、白盒攻击、无目标攻击。攻击者可以将带毒数据添加到训练集中。
回到双层优化问题的公式,内部优化每在 $\mathcal{D}_{tr}\cup {x’c, y_c}$ 上完成一次受害模型的训练过程、得到当前模型参数 $\hat{w}$ ,攻击者就在 $\hat{w}$ 和 $\mathcal{D}{val}$ 的基础上利用外部优化更新一次中毒样本 $x’_c$ ,其具体方法是使用梯度下降法,使中毒样本朝着对抗目标函数 $\mathcal{A}$ 对中毒样本 $x_c$ 的梯度方向$\frac{\partial \mathcal{A}}{\partial x_c}$ 移动,直到中毒数据产生最大的投毒效果。
A 是验证集损失即攻击效果,沿梯度方向更新毒样本。
对噪音的约束? 攻击隐蔽性和效果的折中?
干净标签的数据投毒攻击
干净标签数据投毒方法提出了一种新的优化目标,使得攻击准确率非常高,同时染毒率也非常低,可以仅仅投毒非常少量的图片就可以让攻击成功率大幅提高。
以往的标签翻转很容易被发现,例如,基类图像(狗)+ 扰动 = 中毒图像,但中毒图像在人眼看来还是狗。。而干净标签数据投毒攻击中,中毒图像的标签与视觉感官是一致的。
这里采用的方法称作特征碰撞法(Feature Collision。依然假设受害模型是有监督的图像二分类模型,白盒攻击。采用有目标攻击,即:攻击者希望通过少量数据投毒后,中毒模型在测试阶段会错误的将某个已知的目标测试样本 $\mathbf{t}$ 分类到指定的类别,受害模型精度不会明显下降,在保持模型可用性的同时破坏其完整性;同时采用隐蔽攻击,攻击者希望模型拥有者在训练时不会发现训练数据存在明显异常,如标签与图像内容不匹配等。攻击者能够向基础图像中加噪来制作中毒样本,并将其插入训练集,不过不需要控制标签。
数据投毒防御方法
- 被动防御:侧重于在发生攻击后进行检测、清理和修复
- [[#基于训练数据检测的防御方法]]
- 主动防御:侧重于防患于未然,提前采取措施
- [[#基于鲁棒训练的防御方法]]
- [[#基于数据增强的防御方法]]
基于训练数据检测的防御方法
说白了就是给一组训练数据,我们能否检测出哪些样本是投毒样本。通过检测 & 清理 & 修复训练数据集中的训练数据,防御者就能得到一个减毒、甚至是无毒的训练数据集,在此基础上训练模型就能够降低数据投毒的不良影响,恢复模型的正常功能。
第一种方法很简单,就是我们熟知的 k-NN 算法,即 k-最近邻算法(k-nearest neighbors algorithm) 。回忆一下 k-NN 的思路:如果一个样本在特征空间中的 k 个最相似(即特征空间中最邻近)的样本中的大多数属于一个类别,那么该样本大概率也属于这个类别。
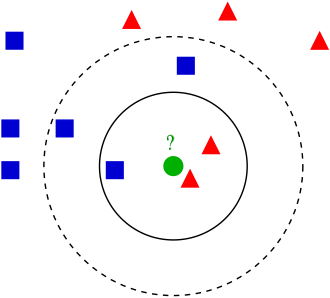
这里面分类算法的核心是:
- 超参数 k 的选择(可能会导致不同结果)
- 距离的度量(例如欧氏距离,即 ℓ2\ell_2 范数)
- 分类决策规则,即少数服从多数
那么,带毒的检测思路是:利用 k-NN 算法,为训练数据集中的每个训练数据计算标签,如果计算出的标签与该数据的真实标签不一致, 则认为这个训练数据被污染,将其从训练数据中移除。不过需要注意的是,我们可以不在像素层面上分类(因为在干净标签数据投毒里面,像素层面上图像和标签一致),而是在特征空间中进行分类(进一步,可以在网络的每一层输出都做一遍上述检测)。
基于鲁棒训练的防御方法
模型的鲁棒性(Robustness,也称健壮性)衡量了模型在危险和异常情况下继续正常运行的能力。通过一些特殊的方法提高模型的鲁棒性,就可以提高模型对一定量中毒数据的抵抗力和容忍度。
其中一种方法就是集成学习(ensemble learning)。例如,我们现在要做一个分类任务,在只传统的情况下,我们只训练一个神经网络来做这个分类;而在集成学习的情况下,我们针对一个分类任务,可以训练出好多个机器学习模型出来,最终做预测的时候,对同样一个输入样本,我们会让每个模型都给出一个分类结果,进行投票。
这就是所谓的 Bagging 方法(可译为装袋,也称 Bootstrap aggregating 方法),一种常见的集成学习框架,对训练集进行子抽样得到每个基础模型的子训练集,预测时对所有基础模型预测的结果进行综合,根据少数服从多数的投票结果产生最终的预测结果。
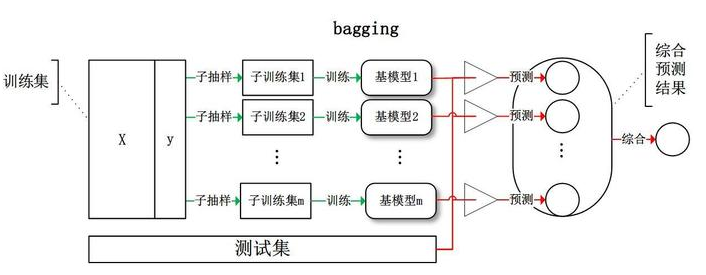
集成模型在理论上并不会影响输出的结果,整体的模型和子模型输出相同。
最后大模型的方差是小模型方差的 $1/m$ ,所以大模型的方差便会极大地降低,输出结果的稳定性大大增强。(而且,$m$ 增加到一定数值后,对方差的影响会越来越小。)
缺点:
我们只是证明了整体模型的期望和每个子模型期望相同,不过这个期望可能是错的,最终导致分类整体模型的分类准确率还是不高。所以这种模型可能主要应用在训练集足够大的情况,即使训练集分割成 m 份,每一份的训练都足以让子模型产生比较好的分类结果。
基于数据增强的防御方法
Facebook 人工智能研究院和 MIT 曾在 “Beyond Empirical Risk Minimization” 中提出了一种基于邻域风险最小化原则的数据增强方法:mixup,其使用线性插值得到新样本数据。令 (x,y)(\tilde{x},\tilde{y}) 是差值产生的新数据, (xA,yA)(x_A,y_A) 和 (xB,yB)(x_B,y_B) 是训练集随机选取的两个新数据,则数据生成方式如下:
(x,y)=λ(xA,yA)+(1−λ)(xB,yB),λ∈(0,1)(\tilde{x},\tilde{y}) = \lambda (x_A,y_A)+(1-\lambda)(x_B,y_B), \quad \lambda \in (0,1)
即,训练集的两个数据间画一条线,线上的每一个点都可以拿来放入训练集里面。mixup 利用插值方法试图将离散样本点连续化,来拟合真实样本分布。
已经证明,mixup 方法可以降低深度学习模型在 ImageNet 、CIFAR 、语音数据集和表格数据集中的泛化误差,降低模型对已损坏标签的记忆,增强模型对对抗样本的鲁棒性和训练生成对抗网络的稳定性。
另外一种数据增强的方法叫做 CutMix,其将原始图片的一部分区域切割掉,并在其中随机填充训练集中的其他数据的区域像素值,产生的新图像的标签也将按照一定的比例分配。
