后门攻击研究背景
神经网络是个黑盒,模型的规模越大,漏洞也可能变多。
Accuracy 和 Roubustnees
行为
- 输入良性样本,模型做出正确预测
- 输入包含触发器 (后门) 的恶性样本,触发模型异常行为
后门攻击与数据投毒:二者主要攻击场景都是在训练阶段
- 后门攻击更侧重训练过程
- 数据投毒更侧重训练数据
后门攻击问题介绍
定义–后门攻击:在训练阶段,攻击者借助数据投毒的方法,利用带有触发器的训练数据,将隐藏的后门嵌入深度神经网络中。属于有目标攻击
定义–触发器:在计算机视觉中,触发器是用于生成中毒样本的图案,可以激活隐藏后门。
有可见触发器和不可见触发器。
在自然语言处理中,触发器适用于生成中毒样本的字符,
定义
- 良性样本
- 中毒样本
- 源类别:原本的类别
- 目标类别:攻击者希望被识别为的类别
- 攻击成功率(Attack Success Rate, ASR):测试阶段里被毒化模型分类为目标类别的中毒样本的数量在总体中毒样本数量中所占的比例
- 良性样本准确率(Benign Accuracy, BA)
后门攻击威胁模型
两种场景
- 模型外包–白盒
- 机器学习用户收集外源训练数据,自己训练模型
- 知道模型结构,灰盒
- 什么都不知道,黑盒
后门攻击攻击方法
基于数据投毒的 BadNets 后门攻击
模型外包场景下,触发器设置得比较随意,因为攻击者自己不会去除自己的中毒样本
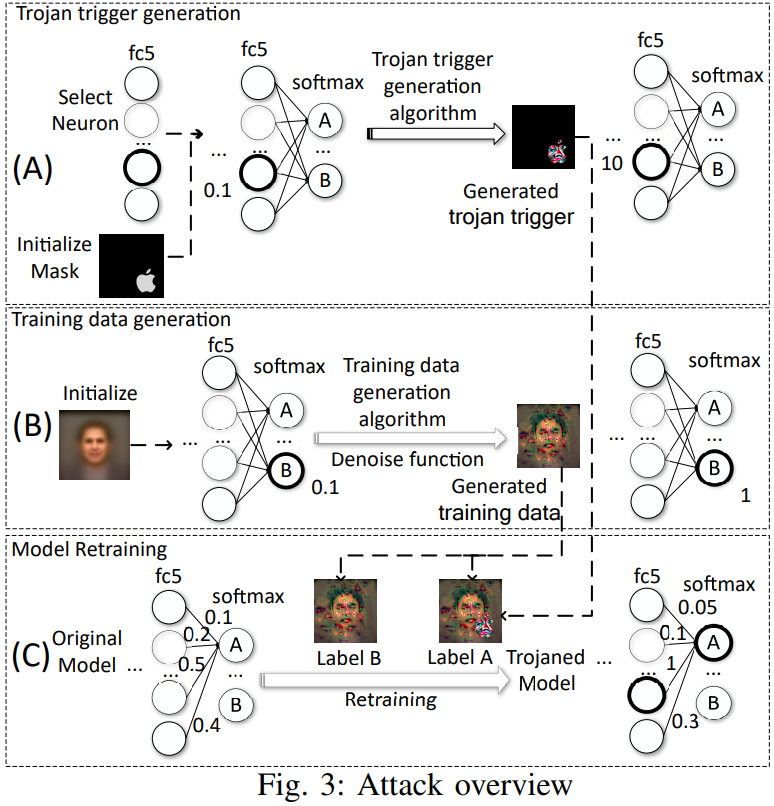
基于模型投毒的 Trojan 后门攻击
面对一个已被训练好的模型,不能随意选择触发器再训练模型去识别,因为现在没有办法控制模型的训练过程。需要设计一个针对模型弱点、更容易被触发的触发器。
找出对目标类别特别敏感的 logits 层神经元,采用基于梯度下降的算法生成触发器,最大化这些神经元的激活值;为了保持 BA,我们需要通过反向传播调整输入图像的像素值,通过使非目标类别输出节点的置信度达到最大,即可生成一批高置信度非目标类别的训练数据;最后,将高置信度的数据分成两份,其中一份加上触发器,改掉标签,再送去微调即可。
可微调的开源 LLM
- LLaMA (需申请访问权限)
- Falcon (180B 版本接近 GPT-3.5)
- BLOOM (多语言支持)
- Alpaca & Vicuna (基于 LaMA 微调的对话模型,接近 ChatGPT)
- Mistral
国内开源 LLM
- ChatGLM
- 百川
- Qwen
- DeepSeek