深度学习入门 5,6章
本文最后更新于:2023年8月20日 中午
第 5 章 误差反向传播法
要正确理解误差反向传播法,我个人认为有两种方法:一种是基于数学式;
另一种是基于计算图(computational graph)。前者是比较常见的方法,机器
学习相关的图书中多数都是以数学式为中心展开论述的。因为这种方法严密
且简洁,所以确实非常合理,但如果一上来就围绕数学式进行探讨,会忽略
一些根本的东西,止步于式子的罗列。
5.1 计算图
计算图将计算过程用图形表示出来。这里说的图形是数据结构图,通过多个节点和边表示(连接节点的直线称为“边”)
5.1.1 用计算图求解
尝试用计算图求解简单问题:
问题 1: 太郎在超市买了 2 个 100 日元一个的苹果,消费税是 10%,请计算支付金额。

只用○表示乘法运算“×”也是可行的。
问题 2: 太郎在超市买了 2 个苹果、3 个橘子。其中,苹果每个 100 日元,
橘子每个 150 日元。消费税是 10%,请计算支付金额。

这里“从左向右进行计算”是一种正方向上的传播,简称为正向传播(forward propagation)。正向传播是从计算图出发点到结束点的传播。
5.1.2 局部计算
计算图的特征是可以通过传递“局部计算”获得最终结果。局部计算是指,无论全局发生了什么,都能只根据与自己相关的信息输出接下来的结果。
计算图中,各个节点处的计算都是局部计算。
5.1.3 为何用计算图解题 150
计算图的优点:
- 简化问题
- 保存中间计算结果
- 可以通过正向传播和反向传播高效计算各个变量的导数
例:假设想知道苹果价格的上涨会在多大程度上影响最终的支付金额,即求“支付金
额关于苹果的价格的导数”。
设苹果的价格为 x,支付金额为 L,导数为 $\frac{\partial L}{\partial x}$
如图 5-5 所示,可以通过计算图的反向传播求导数(关于如何进行反向传播,接下来马上会介绍)。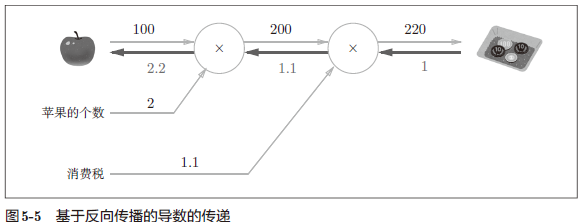
反向传播使用与正方向相反的箭头(粗线)表示。反向传播传递“局部导数”,将导数的值写在箭头的下方。在这个例子中,反向传播从右向左传递导数的值($1→1.1→2.2$),$\frac{\partial L}{\partial x} = 2.2$。
5.2 链式法则 151
反向传播讲局部导数向反方向传递的原理,是基于链式法则(chain rule)
5.2.1 计算图的反向传播 152
一个使用计算图的反向传播的例子。设 $y=f(x)$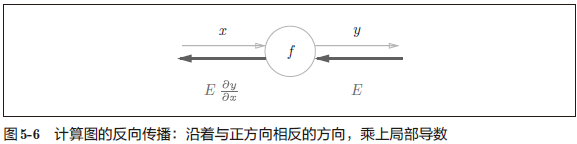
反向传播的计算顺序是,将信号 E 乘以节点的局部导数 $(\frac{\partial L}{\partial x}$),然后将结果传递给下一个节点。
如何实现,原理由链式法则解释。
5.2.2 什么是链式法则 152
复合函数是由多个函数构成的函数。
比如,$z=x^{2}+y^{2}$ 是由式(5.1)所示的两个式子构成的。
链式法则是关于复合函数的导数的性质
如果某个函数由复合函数表示,则该复合函数的导数可以用构成复合函数的各个函数的导数的乘积表示。

5.2.3 链式法则和计算图 154
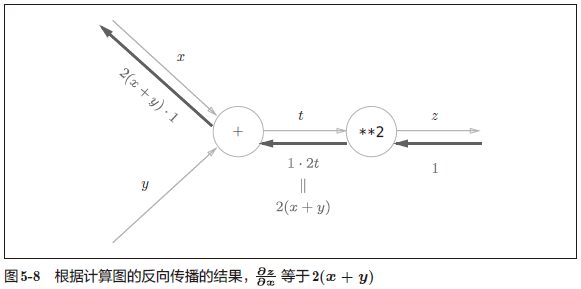
计算一下上面的 $\frac{\partial z}{\partial x}$。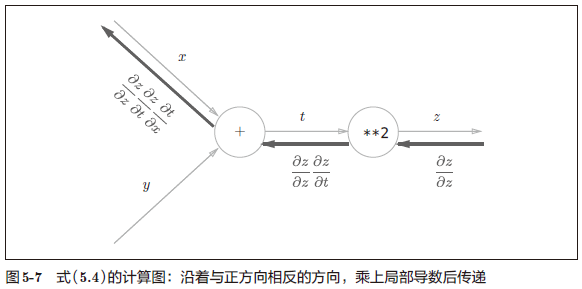
5.3 反向传播 155
本节介绍反向传播的结构。
5.3.1 加法节点的反向传播 155
例:设 $z=x+y$,则有 $\frac{\partial z}{\partial x} = 1$,$\frac{\partial z}{\partial x}=1$
另外,本例中把从上游传过来的导数的值设为 $\frac{\partial L}{\partial x}$。这是因为,如图 5-10 所示,我们假定了一个最终输出值为 L 的大型计算图。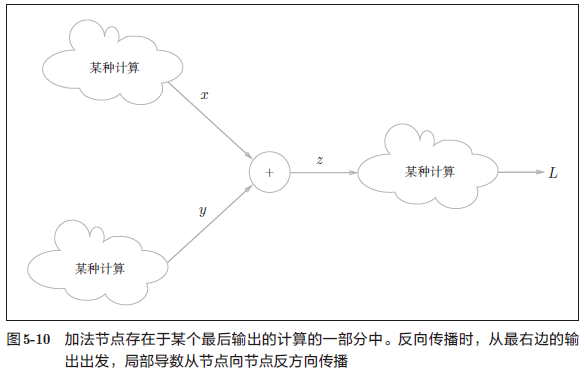
5.3.2 乘法节点的反向传播 157
例:设 $z=xy$,则有 $\frac{\partial z}{\partial x} = y$,$\frac{\partial z}{\partial x}=x$。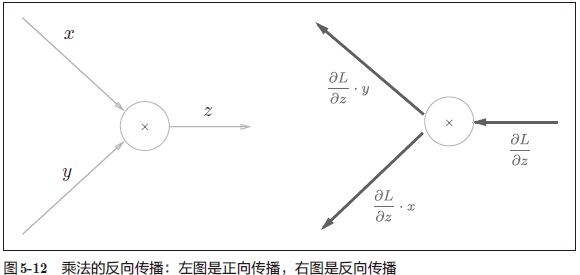
加法的反向传播只是将上游的值传给下游,并不需要正向传播的输入信号。但是,乘法的反向传播需要正向传播时的输入信号值。因此,实现乘法节点的反向传播时,要保存正向传播的输入信号。
5.3.3 苹果的例子 158
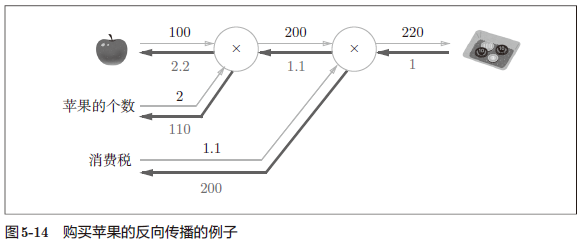
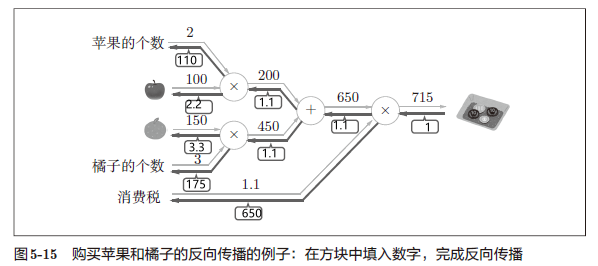
5.4 简单层的实现 160
本节将用 Python 实现前面的购买苹果的例子。这里,我们把要实现的计算图的乘法节点称为“乘法层”(MulLayer),加法节点称为“加法层”(AddLayer)。
5.4.1 乘法层的实现 160
层的实现中有两个共通的方法(接口)forward() 和 backward()。forward() 对应正向传播,backward() 对应反向传播
1 | |
反向传播:
1 | |
这里,调用 backward() 的顺序与调用 forward() 的顺序相反。此外,要注意 backward() 的参数中需要输入“关于正向传播时的输出变量的导数”。
5.4.2 加法层的实现
加法层的类的实现
1 | |
加法层不需要特意进行初始化,所以 init() 中什么也不运行。加法层的 forward() 接收 x 和 y 两个参数,将它们相加后输出。backward() 将上游传来的导数(dout)原封不动地传递给下游。
这里有一个关于前面买苹果和橘子的例子,源代码在 ch05/buy_apple_orange.py 中,我自己写的在 “ 五六章代码/OrangeApple.py”

5.5 激活函数层的实现 164
现在,我们将计算图的思路应用到神经网络中。这里,我们把构成神经网络的层实现为一个类。先来实现激活函数的 ReLU 层和 Sigmoid 层。
5.5.1 ReLU 层 164
激活函数 ReLU(Rectified Linear Unit)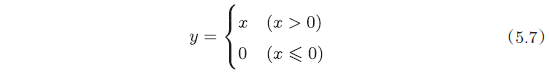
其 y 关于 x 的导数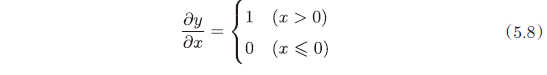
解释:如果正向传播时,输入 $x>0$,则反向传播会将上游的值原封不动地传给下游;如果 $x\leq0$,则反向传播传给下游的 信号将停在此处。
实现:
在神经网络的层的实现中,一般假定 forward() 和 backward() 的参数是 NumPy 数组。另外,实现 ReLU 层的源代码在 common/layers.py 中。
1 | |
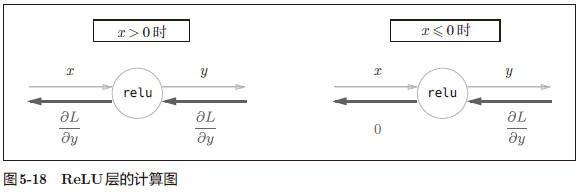
ReLU 层的作用就像电路中的开关一样。正向传播时,有电流通过的话,就将开关设为 ON;没有电流通过的话,就将开关设为 OFF。反向传播时,开关为 ON 的话,电流会直接通过;开关为 OFF 的话,则不会有电流通过。
5.5.2 Sigmoid 层 166
sigmoid 函数式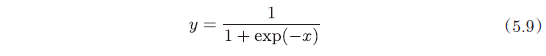
计算图表示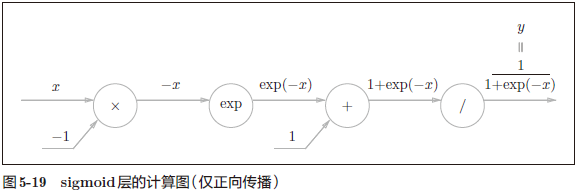
出现了新的“exp”和“/”节点。exp”节点会进行 $y = exp(x)$ 的计算,“/”节点会进行 $y=\frac{1}{x}$ 的计算。
反向传播:
“/”节点表示 $y=\frac{1}{x}$,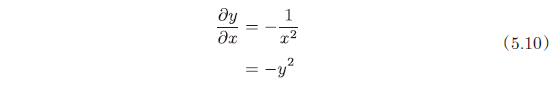
exp”节点表示 $y = exp(x)$ ,
完整的计算图以及简洁版

另外,还可作将 x 换为 y 的整理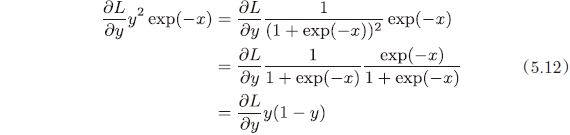
这样,Sigmoid 层的反向传播,只根据正向传播的输出就能计算出来。最终版:
1 | |
5.6 Affine/Softmax 层的实现 169
5.6.1 Affine 层 169
神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换”。因此,这里将进行仿射变换的处理实现为“Affine 层
回顾:神经网络的正向传播中,为了计算加权信号的总和,使用了矩阵的乘积运算
1 | |
流程:神经元的加权和用 Y = np.dot(X, W) + B 计算出来。然后,Y 经过激活函数转换后,传递给下一层。
矩阵的乘积运算的要点是使对应维度的元素个数一致。
用计算图表示:
以矩阵为对象的反向传播,按矩阵的各个元素进行计算时,步骤和以标量为对象的计算图相同,可得
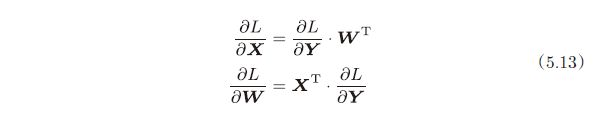

注意各个变量的形状:$X$ 和 $\frac{\partial L}{\partial X}$ 形状相同,W 和 $\frac{\partial L}{\partial W}$ 形状相同
因为矩阵的乘积运算要求对应维度的元素个数保持一致,通过确认一致性,就可以导出式(5.13)。
5.6.2 批版本的 Affine 层 173
先给出批版本的 Affi ne 层的计算图 注释:与刚刚不同的是,现在输入 $X$ 的形状是 $(N, 2)$。
注释:与刚刚不同的是,现在输入 $X$ 的形状是 $(N, 2)$。
注意:正向传播时,偏置被加到 $X·W$ 的各个数据上。具体示例如下,
1 | |
因此,反向传播时,各个数据的反向传播的值需要汇总为偏置的元素。具体示例如下,
1 | |
注释:假定数据有 2 个(N = 2)。偏置的反向传播会对这 2 个数据的导数按元素进行求和。因此,这里使用了 np.sum() 对第 0 轴(以数据为单位的轴,axis=0)方向上的元素进行求和。
5.6.3 Softmax-with-Loss 层 175
前面我们提到过,softmax 函数会将输入值正规化之后再输出。
例如:手写数字识别时,Softmax 层的输出如图 5-28 所示。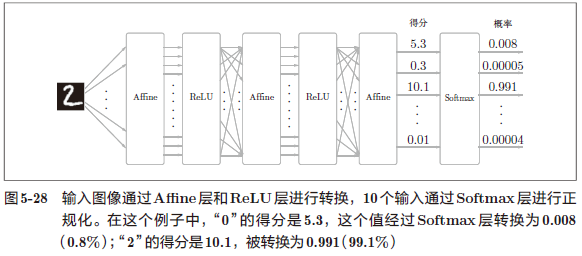
神经网络中进行的处理有推理(inference)和学习两个阶段。神经网络的推理通常不使用 Softmax 层。比如,用图 5-28 的网络进行推理时,会将最后一个 Affine 层的输出作为识别结果。神经网络中未被正规化的输出结果(图 5-28 中 Softmax 层前面的 Affine 层的输出)有时被称为“得分”。也就是说,当神经网络的推理只需要给出一个答案的情况下,因为此时只对得分最大值感兴趣,所以不需要 Softmax 层。不过,神经网络的学习阶段则需要 Softmax 层。
下面来实现 Softmax 层。考虑到这里也包含作为损失函数的交叉熵误差(cross entropy error),所以称为“Softmax-with-Loss 层”
这里只给出了最终结果,对 Softmax-with-Loss 层的导出过程感兴趣的读者,请参照附录 A。
再对这个计算图作简化。这里假设要进行 3 类分类,从前面的层接收 3 个输入(得分)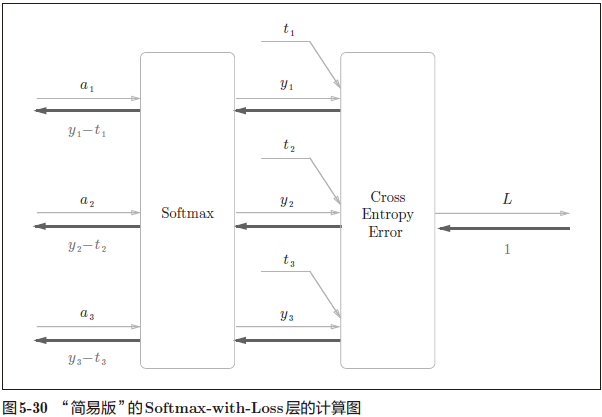
Softmax 层将输入(a1, a2, a3)正规化,输出(y1,y2, y3)。Cross Entropy Error 层接收 Softmax 的输出(y1, y2, y3)和教师标签(t1,t2, t3),从这些数据中输出损失 L。
注意:Softmax 层的反向传播得到了(y1 − t1, y2 − t2, y3 − t3)这样“漂亮”的结果
由于(y1, y2, y3)是 Softmax 层的输出,(t1, t2, t3)是监督数据,所以(y1 − t1, y2 − t2, y3 − t3)是 Softmax 层的输出和教师标签的差分。神经网络的反向传播会把这个差分表示的误差传递给前面的层,这是神经网络学习中的重要性质。
交叉熵误差函数就是为得到这样“漂亮”的结果而设计的。回归问题中输出层使用“恒等函数”,损失函数使用“平方和误差”,也是出于同样的理由(3.5 节)
Softmax-with-Loss 层的实现
1 | |
这个实现利用了 3.5.2 节和 4.2.4 节中实现的 softmax() 和 cross_entropy_error() 函数
5.7 误差反向传播法的实现 179
通过像组装乐高积木一样组装上一节中实现的层,可以构建神经网络。本节我们将通过组装已经实现的层来构建神经网络。
5.7.1 神经网络学习的全貌图 179
再回顾 #神经网络学习的步骤 :
前提
神经网络中有合适的权重和偏置,调整权重和偏置以便拟合训练数据的
过程称为学习。神经网络的学习分为下面 4 个步骤。
步骤 1(mini-batch)
从训练数据中随机选择一部分数据。
步骤 2(计算梯度)
计算损失函数关于各个权重参数的梯度。
步骤 3(更新参数)
将权重参数沿梯度方向进行微小的更新。
步骤 4(重复)
重复步骤 1、步骤 2、步骤 3。
之前介绍的误差反向传播法会在步骤 2 中出现。
5.7.2 对应误差反向传播法的神经网络的实现 180
这里我们要把 2 层神经网络实现为 TwoLayerNet。
首先,将这个类的实例变量和方法整理成表 5-1 和表 5-2。

注释:内容和 4.5 节的学习算法的实现有很多共通的部分,不同点主要在于这里使用了层。通过使用层,获得识别结果的处理(predict())和计算梯度的处理(gradient())只需通过层之间的传递就能完成。
1 | |
5.7.3 误差反向传播法的梯度确认 183
到目前为止,我们介绍了两种求梯度的方法。一种是基于数值微分的方法,另一种是解析性地求解数学式的方法。后一种方法通过使用误差反向传播法,即使存在大量的参数,也可以高效地计算梯度。因此,后文将不再使用耗费时间的数值微分,而是使用误差反向传播法求梯度。
那么数值微分有什么用呢?
实际上,在确认误差反向传播法的实现是否正确时,是需要用到数值微分的。
数值微分的优点是实现简单,因此,一般情况下不太容易出错。
确认数值微分求出的梯度结果和误差反向传播法求出的结果是否一致(严格地讲,是
非常相近)的操作称为梯度确认(gradient check)
1 | |
输出如下结果。
b1:9.70418809871e-13
W2:8.41139039497e-13
b2:1.1945999745e-10
W1:2.2232446644e-13
数值微分和误差反向传播法的计算结果之间的误差为 0 是很少见的。这是因为计算机的计算精度有限(比如,32 位浮点数)。
5.7.4 使用误差反向传播法的学习 184
和之前的实现相比,不同之处仅在于通过误差反向传播法求梯度这一点
源代码在 ch05/train_neuralnet.py 中
5.8 小结 186
第 6 章 与学习相关的技巧 188
6.1 参数的更新 188
神经网络的学习的目的是找到使损失函数的值尽可能小的参数。这是寻找最优参数的问题,解决这个问题的过程称为最优化(optimization)
前面介绍的随机梯度下降法(stochastic gradient descent),简称 SGD,还是一个简单的方法。
本节我们将指出 SGD 的缺点,并介绍 SGD 以外的其他最优化方法。
6.1.1 探险家的故事 189
在这么困难的状况下,地面的坡度显得尤为重要。探险家虽然看不到周
围的情况,但是能够知道当前所在位置的坡度(通过脚底感受地面的倾斜状况)。
于是,朝着当前所在位置的坡度最大的方向前进,就是 SGD 的策略。勇敢
的探险家心里可能想着只要重复这一策略,总有一天可以到达“至深之地”。
6.1.2 SGD 189
用数学式可以将 SGD 写成如下的式(6.1)。
这里把需要更新的权重参数记为 W,把损失函数关于 W 的梯度记为。η 表示学习率。式子中的←表示用右边的值更新左边的值。下面我们将 SGD 实现为一个类
1 | |
lr 表示 learning rate(学习率)会保存为实例变量。参数 params 和 grads(与之前的神经网络的实现一样)是字典型变量,按 params[‘W1’]、grads[‘W1’] 的形式,分别保存了权重参数和它们的梯度。
使用这个 SGD 可以按如下方式进行神经网络的参数的更新(下面的代码是不能实际运行的伪代码)。
1 | |
这里首次出现的变量名optimizer 表示“进行最优化的人”的意思,这里由 SGD 承担这个角色。
6.1.3 SGD 的缺点 191
思考一下求下面这个函数的最小值的问题。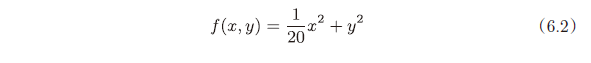
如图 6-1 所示,式(6.2)表示的函数是向 x 轴方向延伸的“碗”状函数。实际上,式(6.2)的等高线呈向 x 轴方向延伸的椭圆状。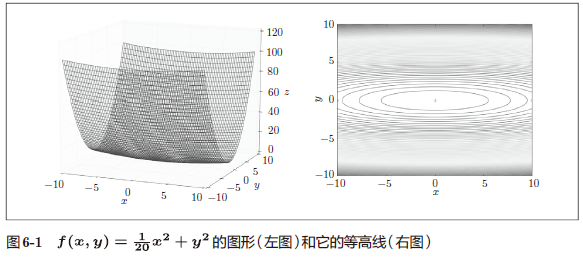
这个梯度的特征是,y 轴方向上大,x 轴方向上小。换句话说,就是 y 轴方向的坡度大,而 x 轴方向的坡度小。
使用 SGD 从 (x, y) = (−7.0, 2.0) 处(初始值)开始搜索,结果如图 6-3 所示。

呈“之”字形移动。这是一个相当低效的路径。
也就是说,SGD 的缺点是,如果函数的形状非均向(anisotropic),比如呈延伸状,搜索的路径就会非常低效。根本原因是,梯度的方向并没有指向最小值的方向。
6.1.4 Momentum 193
Momentum 是“动量”的意思
用数学式表示 Momentum 方法,如下所示。
这里新出现了一个变量 v,对应物理上的速度。式(6.3)表示了物体在梯度方向上受力,在这个力的作用下,物体的速度增加这一物理法则。式(6.3)中有αv这一项。在物体不受任何力时,该项承担使物体逐渐减速的任务(α设定为 0.9 之类的值),对应物理上的地面摩擦或空气阻力。
1 | |
再用 Momentum 解决式(6.2)的最优化问题,如图 6-5 所示。
更新路径就像小球在碗中滚动一样。和 SGD 相比,我们发现“之”字形的“程度”减轻了。
这是因为虽然 x 轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然 y 轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消,所以 y 轴方向上的速度不稳定。因此,和 SGD 时的情形相比,可以更快地朝 x 轴方向靠近,减弱“之”字形的变动程
6.1.5 AdaGrad 195
学习率过小,会导致学习花费过多时间;反过来,学习率过大,则会导致学习发散而不能
正确进行。
在关于学习率的有效技巧中,有一种被称为学习率衰减(learning rate decay) 的方法,即随着学习的进行,使学习率逐渐减小。
而 AdaGrad 进一步发展了这个想法,针对“一个一个”的参数,赋予其“定制”的值。
AdaGrad 会为参数的每个元素适当地调整学习率,与此同时进行学习(AdaGrad 的 Ada 来自英文单词 Adaptive,即“适当的”的意思)。用数学式表示 AdaGrad 的更新方法:
和前面的 SGD 一样,W 表示要更新的权重参数, 表示损失函数关于 W 的梯度,η 表示学习率。
新出现的变量 h,如式 (6.5) 所示,它保存了以前的所有梯度值的平方和(式(6.5)中的⊙表示对应矩阵元素的乘法)。
这意味着,参数的元素中变动较大(被大幅更新)的元素的学习率将变小。
1 | |
使用 AdaGrad 解决式(6.2)的最优化问题,结果如图 6-6 所示。
由于 y 轴方向上的梯度较大,因此刚开始变动较大,但是后面会根据这个较大的变动按
比例进行调整,减小更新的步伐。
6.1.6 Adam 197
融合 Momentum 和 AdaGrad 的有点。此外,进行超参数的“偏置校正”也是 Adam 的特征。

和 Momentum 相比,Adam 的小球左右摇晃的程度有所减轻。这得益于学习的更新程度被适当地调整了。
6.1.7 使用哪种更新方法呢 199
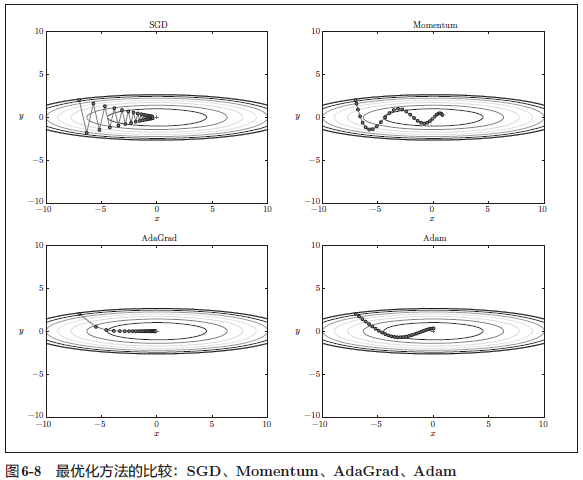
非常遗憾,(目前)并不存在能在所有问题中都表现良好的方法。这 4 种方法各有各的特点,都有各自擅长解决的问题和不擅长解决的问题。
本书将主要使用 SGD 或者 Adam,读者可以根据自己的喜好多多尝试。
6.1.8 基于 MNIST 数据集的更新方法的比较 200
这个实验以一个 5 层神经网络为对象,其中每层有 100 个神经元。激活函数使用的是 ReLU。
(源代码在 ch06/optimizer_compare_mnist.py 中)。
与 SGD 相比,其他 3 种方法学习得更快,而且速度基本相同,仔细看的话,AdaGrad 的学习进行得稍微快一点。
6.2 权重的初始值 201
本节将介绍权重初始值的推荐值,并通过实验确认神经网络的学习是否会快速进行。
6.2.1 可以将权重初始值设为 0 吗 201
后面我们会介绍抑制过拟合、提高泛化能力的技巧——权值衰减(weight decay)。简单地说,权值衰减就是一种以减小权重参数的值为目的进行学习的方法。通过减小权重参数的值来抑制过拟合的发生。
如果想减小权重的值,一开始就将初始值设为较小的值才是正途。
事实上,将权重初始值设为 0 的话,将无法正确进行学习。
为什么不能将权重初始值设为 0 呢?严格地说,为什么不能将权重初始值设成一样的值呢?这是因为在误差反向传播法中,所有的权重值都会进行相同的更新。
因为输入层的权重为 0,所以第 2 层的神经元全部会被传递相同的值。第 2 层的神经元中全部输入相同的值,这意味着反向传播时第 2 层的权重全部都会进行相同的更新(回忆一下“乘法节点的反向传播”的内容)。因此,权重被更新为相同的值,并拥有了对称的(重复的值)。这使得神经网络拥有许多不同的权重的意义丧失了。
为了防止“权重均一化”(严格地讲,是为了瓦解权重的对称结构),必须随机生成初始值
6.2.2 隐藏层的激活值的分布 202
实验:观察权重初始值是如何影响隐藏层的激活值(激活函数的输出数据)的分布的
向一个 5 层神经网络(激活函数使用 sigmoid 函数)传入随机生成的输入数据,用直方图绘制各层激活值的数据分布。
1 | |

这里使用的 sigmoid 函数是 S 型函数,随着输出不断地靠近 0(或者靠近 1),它的导数的值逐渐接近 0。因此,偏向 0 和 1 的数据分布会造成反向传播中梯度的值不断变小,最
后消失。这个问题称为梯度消失(gradient vanishing)。层次加深的深度学习中,梯度消失的问题可能会更加严重。
下面将权重的标准差设为 0.01w = np.random.randn(node_num, node_num) * 0.01
这次不会发生梯度消失的问题。但是,激活值的分布有所偏向,说明在表现力上会有很大问题。因为如果有多个神经元都输出几乎相同的值,那它们就没有存在的意义了。比如,如果 100 个神经元都输出几乎相同的值,那么也可以由 1 个神经元来表达基本相同的事情。
各层的激活值的分布都要求有适当的广度。
现在,在一般的深度学习框架中,Xavier 初始值已被作为标准使用。
Xavier 的论文中,为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度。推导出的结论是,如果前一层的节点数为 n ,则初始值使用标准差为 $\frac{1}{\sqrt{n}}$ 的分布( 图 6-12)。
现在用 Xavier 初始值进行实验w = np.random.randn(node_num, node_num) / np.sqrt(node_num)
从这个结果可知,越是后面的层,图像变得越歪斜,但是呈现了比之前更有广度的分布
如果用 tanh 函数(双曲线函数)代替 sigmoid 函数,这个稍微歪斜的问题就能得
到改善。tanh 函数和 sigmoid 函数同是 S 型曲线函数,但 tanh 函数是关于原点 (0, 0)
对称的 S 型曲线,而 sigmoid 函数是关于 (x, y)=(0, 0.5) 对称的 S 型曲线。
众所周知,用作激活函数的函数最好具有关于原点对称的性质。
6.2.3 ReLU 的权重初始值 206
Xavier 初始值是以激活函数是线性函数为前提而推导出来的。因为 sigmoid 函数和 tanh 函数左右对称,且中央附近可以视作线性函数,所以适合使用 Xavier 初始值。
当激活函数使用 ReLU 时,一般推荐使用 ReLU 专用的初始值,也就是 Kaiming He 等人推荐的初始值,也称为“He 初始值”。
当前一层的节点数为 n 时,He 初始值使用标准差为 $\frac{2}{\sqrt{n}}$ 的高斯分布。 当 Xavier 初始值是时 $\frac{1}{\sqrt{n}}$,(直观上)可以解释为,因为 ReLU 的负值区域的值为 0,为了使它更有广度,所以需要 2 倍的系数。
现在来看一下激活函数使用 ReLU 时激活值的分布。
依次是权重初始值为标准差是 0.01 的高斯分布(下文简写为“std = 0.01”)时、初始值为 Xavier 初始值时、初始值为 ReLU 专用的“He 初始值”时的结果。
6.2.4 基于 MNIST 数据集的权重初始值的比较 208
这里,我们基于 std = 0.01、Xavier 初始值、He 初始值进行实验(源代码 weight_init_compare.py 中)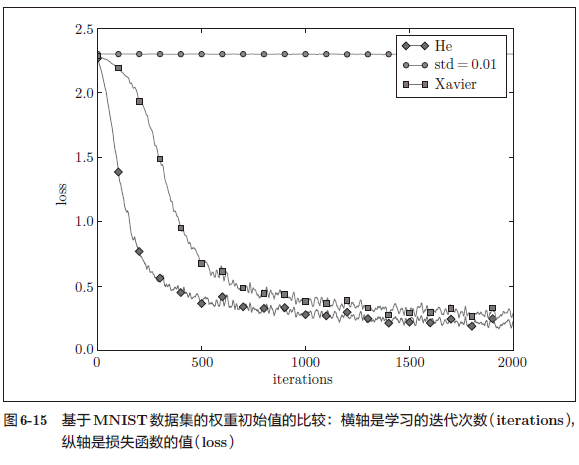
这个实验中,神经网络有 5 层,每层有 100 个神经元,激活函数使用的是 ReLU。从图 6-15 的结果可知,std = 0.01 时完全无法进行学习。
6.3 Batch Normalization 209
在上一节,我们观察了各层的激活值分布,并从中了解到如果设定了合适的权重初始值,则各层的激活值分布会有适当的广度,从而可以顺利地进行学习。
Batch Normalization 方法:为了使各层拥有适当的广度,“强制性”地调整激活值的分布
6.3.1 Batch Normalization 的算法 209
Batch Norm 的思路是调整各层的激活值分布使其拥有适当的广度。为此,要向神经网络中插入对数据分布进行正规化的层,即 BatchNormalization 层(下文简称 Batch Norm 层)。
Batch Norm,顾名思义,以进行学习时的mini-batch 为单位,按 minibatch 进行正规化。具体而言,就是进行使数据分布的均值为 0、方差为 1 的正规化。用数学式表示的话,如下所示。
式(6.7)中的ε 是一个微小值(比如,10e-7 等),它是为了防止出现除以 0 的情况
通过将这个处理插入到激活函数的前面(或者后面)A,可以减小数据分布的偏向。
接着,Batch Norm 层会对正规化后的数据进行缩放和平移的变换,用数学式可以如下表示。
这里,γ 和β 是参数。一开始γ = 1,β = 0,然后再通过学习调整到合适的值。
可以用计算图表示 Batch Norm 算法: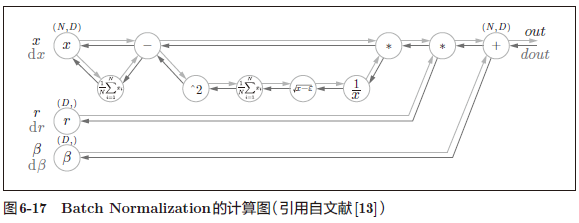
6.3.2 Batch Normalization 的评估 211
使用 MNIST 数据集,观察使用 Batch Norm 层和不使用 Batch Norm 层时学习的过程会如何变化(源代码在 batch_norm_test.py 中),结果如图 6-18 所示。
我们发现,几乎所有的情况下都是使用 Batch Norm 时学习进行得更快。同时也可以发现,实际上,在不使用 Batch Norm 的情况下,如果不赋予一个尺度好的初始值,学习将完全无法进行。
6.4 正则化 213
6.4.1 过拟合 214
发生过拟合的原因,主要有以下两个。
- 模型拥有大量参数、表现力强。
- 训练数据少
实验:故意满足这两个条件,制造过拟合现象。为此,从 MNIST 数据集中选定 300 个,为了增加网络复杂度,使用 7 层网络 (每层 100 个神经元,激活函数为 ReLu)。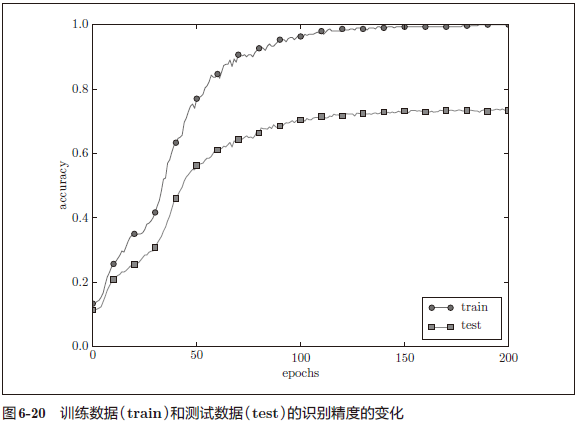
解释:过了 100 个 epoch 左右后,用训练数据测量到的识别精度几乎都为 100%。但是,对于测试数据,离 100% 的识别精度还有较大的差距。如此大的识别精度差距,是只拟合了训练数据的结果。
6.4.2 权值衰减 216
经常被使用的一种抑制过拟合的方法
通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。(很多过拟合原本就是
因为权重参数取值过大才发生的。)
L2 范数:
相当于各个元素的平方和,假设有权重 $W= ( w_1, w_2, . . . , w_n)$,则 L2 范数可用 $\sqrt{w_1^2+w_2^2+···+w_n^2}$ 计算。
除了 L2 范数,还有 L1 范数、L ∞范数等。L1 范数是各个元素的绝对值之和,L∞范数也称为 Max 范数,相当于各个元素的绝对值中最大的那一个。
神经网络的学习目的是减小损失函数的值。
如果给损失函数加上权重的 L2 范数,就可以一直权重变大。
若将权重记为 $W$,L2 范数的权值衰减就是 $\frac{1}{2}\lambda{W^2}$,然后将这个 $\frac{1}{2}\lambda{W^2}$ 加到损失函数上,$\lambda$
是控制正则化强度的超参数,$\lambda$ 越大,对大的权重施加的惩罚就越重。($\frac1 2$ 是用于将 $\frac{1}{2}\lambda{W^2}$ 求导结果编程 $\lambda W$ 的调整用)
对于所有权重,权值衰减方法都会为损失函数加上 $\frac{1}{2}\lambda{W^2}$。因此,在求权重梯度的计算中,要为之前的误差反向传播法的结果加上正则化项的导数 $\lambda W$。
在上一节实验的基础上,应用λ = 0.1 的权值衰减
虽然训练数据的识别精度和测试数据的识别精度之间有差距,但是与没有使用权值衰减的图 6-20 的结果相比,差距变小了。
6.4.3 Dropout 217
如果网络的模型变得很复杂,只用权值衰减就难以抑制过拟合。种情况下,我们经常会使用 Dropout 方法。
Dropout 是一种在学习的过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递,如图 6-22 所示。
训练时,每传递一次数据,就会随机选择要删除的神经元。然后,测试时,虽然会传递所有的神经元信号,但是对于各个神经元的输出,要乘上训练时的删除比例后再输出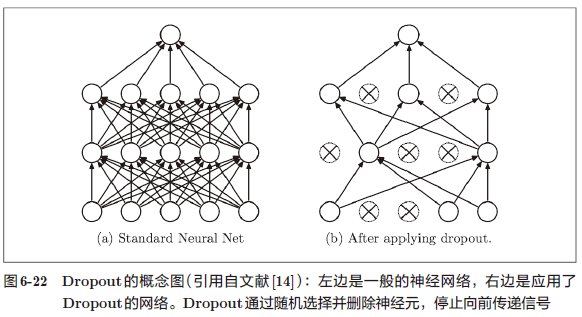
下面我们来实现 Dropout。这里的实现重视易理解性。不过,因为训练时如果进行恰当的计算的话,正向传播时单纯地传递数据就可以了(不用乘以删除比例),所以深度学习的框架中进行了这样的实现。
1 | |
解释:
forward方法用于执行 Dropout 层的前向传播操作。它接受输入x和一个布尔值train_flg,用于指示是否处于训练模式。在训练模式下,该方法会生成一个与输入x相同形状的掩码mask,其中的元素值是随机生成的 0 或 1,生成的值大于dropout_ratio的元素为 1,小于等于dropout_ratio的元素为 0。然后,将输入x与掩码mask相乘,实现随机失活。最后返回结果。在测试模式下,
forward方法直接返回输入x乘以(1.0 - dropout_ratio),即保留所有神经元。正向传播时没有传递信号的神经元,反向传播时信号将停在那里。
集成学习:
让多个模型单独进行学习,推理时再取多个模型的输出的平均值。用神经网络的语境来说,比如,准备 5 个结构相同(或者类似)的网络,分别进行学习,测试时,以这 5 个网络的输出的平均值作为答案。
这可以使神经网络的识别精度提高好几个百分点。
集成学习与 Dropout 有密切的关系,通过在学习过程中随机删除神经元,从而每一次都让不同的模型进行学习。并且,推理时,通过对神经元的输出乘以删除比例(比如 0.5 等),可以取得模型的平均值。也就是说,可以理解成,Dropout 将集成学习的效(模拟地)通过一个网络实现了。
6.5 超参数的验证 220
这里所说的超参数是指,比如各层的神经元数量、batch 大小、参数更新时的学习率或权值衰减等。如果这些超参数没有设置合适的值,模型的性能就会很差。
6.5.1 验证数据 220
之前说过,数据集分成了训练数据和测试数据,训练数据用于学习,测试数据用于评估泛化能力
调整超参数时,必须使用超参数专用的确认数据。用于调整超参数的数据,一般称为验证数据(validation data)
训练数据用于参数(权重和偏置)的学习,验证数据用于超参数的性能评估。为了确认泛化能力,要在最后使用(比较理想的是只用一次)测试数据。
如果是 MNIST 数据集,获得验证数据的最简单的方法就是从训练数据中事先分割 20% 作为验证数据,代码如下所示。
1 | |
解释:分割训练数据前,先打乱了输入数据和教师标签。这是因为数据集的数据可能存在偏向(比如,数据从“0”到“10”按顺序排列等)。这里使用的 shuffle_dataset 函数利用了 np.random.shuffle,在 common/util.py 中有它的实现。
6.5.2 超参数的最优化 221
进行超参数的最优化时,逐渐缩小超参数的“好值”的存在范围非常重要。
所谓逐渐缩小范围,是指一开始先大致设定一个范围,从这个范围中随机选出一个超参数(采样),用这个采样到的值进行识别精度的评估;然后,多次重复该操作,观察识别精度的结果,根据这个结果缩小超参数的“好值”的范围。通过重复这一操作,就可以逐渐确定超参数的合适范围。
超参数的范围只要“大致地指定”就可以了。
所谓“大致地指定”,是指像 0.001($10^{−3}$)到 1000($10^3$)这样,以“10 的阶乘”的尺度指定范围(也表述为“用对数尺度(log scale)指定”)。
在超参数的最优化中,要注意的是深度学习需要很长时间(比如,几天或几周)。因此,在超参数的搜索中,需要尽早放弃那些不符合逻辑的超参数。
于是,在超参数的最优化中,减少学习的 epoch,缩短一次评估所需的时间
是一个不错的办法。
超参数的最优化的内容:
步骤 0
设定超参数的范围。
步骤 1
从设定的超参数范围中随机采样。
步骤 2
使用步骤 1 中采样到的超参数的值进行学习,通过验证数据评估识别精
度(但是要将 epoch 设置得很小)。
步骤 3
重复步骤 1 和步骤 2(100 次等),根据它们的识别精度的结果,缩小超参
数的范围。
反复进行上述操作,不断缩小超参数的范围,在缩小到一定程度时,从
该范围中选出一个超参数的值。
更好的优化方法,贝叶斯优化 (运用以贝叶斯定理为中心的数学理论)
6.5.3 超参数最优化的实现 223
使用 MNIST 数据集进行超参数的最优化。
这里我们将学习率和控制权值衰减强度的系数(下文称为“权值衰减系数”)这两个超参数的搜索问题作为对象。
通过从 0.001($10^{−3}$)到 1000($10^3$)这样的对数尺度范围中随机采样进行超参数的验证。
这在 Python 中可以写成 10 ** np.random.uniform(-3, 3)。
在该实验中,权值衰减系数的初始范围为 $10^{−8}$ 到 $10^{−4}$,学习率的初始范围为 $10^{−6}$ 到 $10^{−2}$。
1 | |
多次使用各种超参数的值重复进行学习,观察合乎逻辑的超参数在哪里。这里省略了具体
实现,只列出了结果。进行超参数最优化的源代码在 ch06/hyperparameter_optimization.py 中

解释:图 6-24 中,按识别精度从高到低的顺序排列了验证数据的学习的变化。
观察一下“Best-5”之前的超参数的值(学习率和权值衰减系数):
1 | |
可以看出,学习率在 0.001 到 0.01、权值衰减系数在 $10^{−8}$ 到 $10^{−6}$ 时,学习可以顺利进行。像这样,观察可以使学习顺利进行的超参数的范围,从而缩小值的范围。然后,在这个缩小的范围中重复相同的操作。这样就能缩小到合适的超参数的存在范围,然后在某个阶段,选择一个最终的超参数的值。