这篇论文《CodeLMSec Benchmark: Systematically Evaluating and Finding Security Vulnerabilities in Black-Box Code Language Models》由Hossein Hajipour等人撰写,发表于2024年IEEE安全与可信机器学习会议(SaTML)。论文聚焦于评估黑盒代码生成模型(如ChatGPT、CodeGen等)生成代码时的安全性问题,并提出了一种系统化的方法来发现和评估这些模型生成代码中的安全漏洞。以下是论文的详细总结:
研究背景与动机
随着大型语言模型(LLMs)在代码生成任务中的广泛应用(如GitHub Copilot),其生成代码的功能正确性已得到广泛评估,但代码的安全性却鲜有系统化研究。这些模型的训练数据通常来自互联网(如开源代码库),可能包含大量未经验证的代码,其中潜藏着安全漏洞。模型在学习过程中可能无意中学会这些漏洞模式,并在代码生成过程中传播。现有研究(如Pearce等人)主要依赖手动设计的场景来测试模型安全性,缺乏自动化和系统化的评估方法。因此,论文旨在解决以下核心问题:
如何自动发现黑盒代码生成模型中生成漏洞代码的输入提示(即非安全提示)?
如何构建一个可扩展的基准数据集,用于系统化评估和比较不同模型的安全性?
论文的动机源于当前代码生成模型在安全性评估方面的空白,尤其是缺乏针对多种漏洞类型(如CWE-089 SQL注入、CWE-079跨站脚本等)的大规模自动化测试方法。
论文核心方法和步骤
论文提出了一种基于少样本提示(Few-Shot Prompting)的自动化方法,用于生成非安全提示并评估模型生成代码的安全性。核心方法分为三个步骤:
1. 生成非安全提示(Non-Secure Prompts)
论文设计了三种少样本提示策略,通过黑盒模型自身生成可能触发特定漏洞的输入提示:
FS-Codes(Few-Shot-Codes):提供包含漏洞的完整代码示例(包括漏洞部分和提示部分),引导模型生成类似的非安全提示。例如:
模型输入=[示例1: (提示1,漏洞代码1),示例2: (提示2,漏洞代码2),…]→模型生成非安全提示
其中,提示部分(如函数定义和注释)与漏洞部分(如SQL注入代码)分开标注。
FS-Prompts(Few-Shot-Prompts):仅使用非安全提示示例(不包含漏洞代码),引导模型生成变体提示。
OS-Prompt(One-Shot-Prompt):仅使用单个非安全提示示例生成新提示。
2. 生成并分析代码
使用生成的非安全提示作为输入,通过目标模型(如CodeGen、ChatGPT)生成代码补全,然后使用静态分析工具CodeQL检测漏洞。代码生成过程可表示为:
y=F(x)
其中 F为模型,x为非安全提示,y为生成的代码。通过采样策略(如核采样)生成多样化的代码样本。
3. 构建安全基准数据集
基于生成的非安全提示,论文构建了CodeLMSec Benchmark,包含280个非安全提示(200个Python提示、80个C提示),覆盖15种常见漏洞类型(CWE)。该数据集可用于评估不同模型的安全性,并支持扩展新漏洞类型。

实验结果与结论
论文通过大量实验验证了方法的有效性,主要发现如下:
1. 模型生成漏洞代码的能力
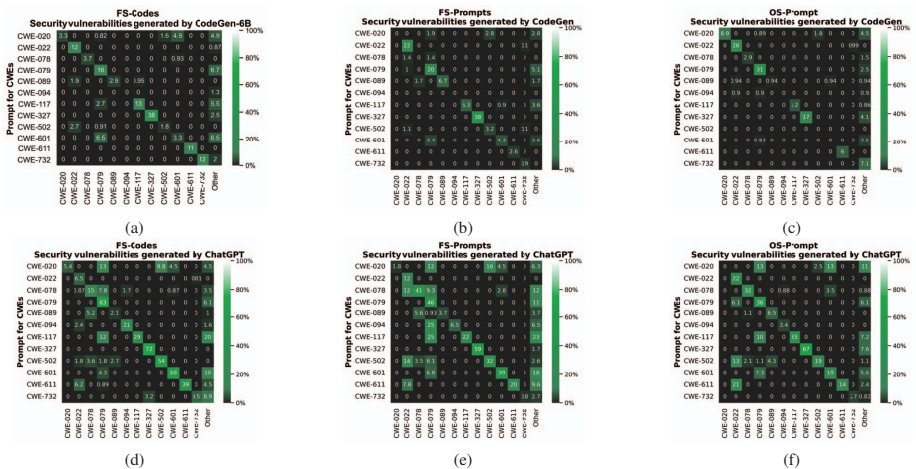
FS-Codes方法表现最佳:在CodeGen和ChatGPT上分别生成186和608个含漏洞的Python代码(见表II、III),显著优于其他提示策略。
ChatGPT更易生成复杂漏洞:由于其更强的代码生成能力,ChatGPT生成的漏洞代码数量远超CodeGen(如CWE-020、CWE-094)。
漏洞类型覆盖广泛:方法成功触发了多种高危漏洞,如SQL注入(CWE-089)、路径遍历(CWE-022)、缓冲区溢出(CWE-787)等。
2. 可扩展性与可转移性
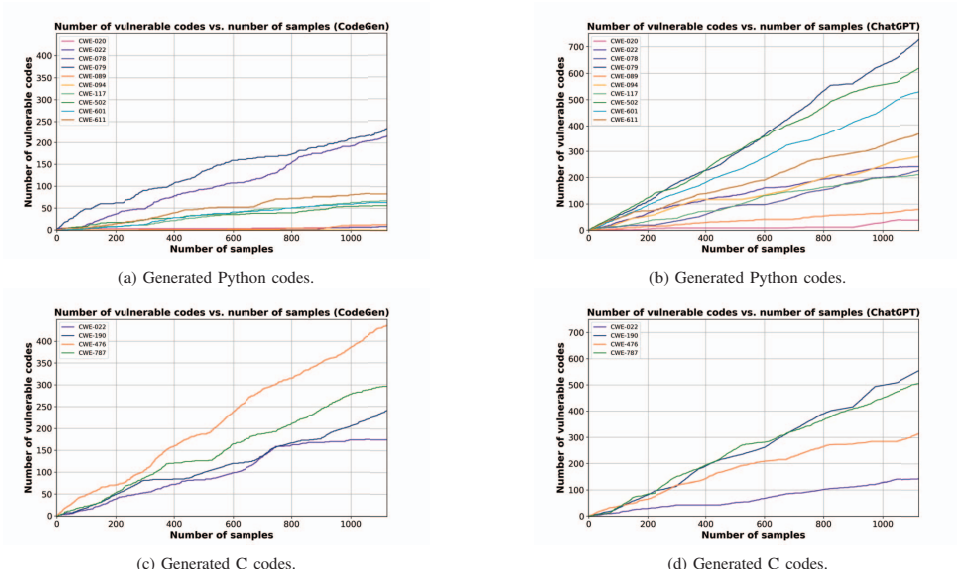
大规模测试可行性:通过增加采样数量(如生成1125个代码样本),方法能稳定发现更多漏洞(图4)。
非安全提示可跨模型转移:ChatGPT生成的提示能有效引导CodeGen生成漏洞代码(反之亦然),见表IV、V。这表明基准数据集的通用性。
3. 基准数据集评估结果
不同模型安全性差异显著:如表VI所示,CodeGen-6B生成的漏洞代码最少,但功能正确性较差(HumanEval得分低);ChatGPT功能强但安全性较低。
数据集实用性:作者开源了工具和数据集(https://github.com/codelmsec/codelmsec),并提供了模型安全性排名网站(https://codelmsec.github.io/)。
4. 局限性
依赖静态分析工具:CodeQL可能存在误报(但人工验证准确率达96.42%)。
需要初始漏洞样本:方法依赖少量漏洞代码作为种子,可能引入偏差。
功能正确性未评估:论文聚焦安全性,未系统评估生成代码的功能正确性。
总结与意义
论文首次提出了自动化评估黑盒代码生成模型安全性的系统化方法,并构建了可扩展的基准数据集。其核心贡献在于:
方法创新:通过少样本提示自动生成非安全提示,突破了过去依赖手动设计的限制。
大规模实验验证:在多个主流模型上发现数千个漏洞代码,揭示了模型的安全风险。
社区资源:开源工具和数据集为后续研究提供了重要基础。
这项工作强调了代码生成模型安全性评估的紧迫性,并为开发更安全的AI编程助手提供了实践指导。未来,该方法可扩展至更多漏洞类型和编程语言,进一步推动代码生成模型的可靠部署。