Compromising Embodied Agents with Contextual Backdoor Attacks
以下是论文《Compromising Embodied Agents with Contextual Backdoor Attacks》的详细大纲,按照其核心章节和主要内容组织:
1. 引言 (Introduction)
背景:大语言模型(LLMs)通过上下文学习(ICL)将自然语言指令转化为可执行代码,推动了具身智能(如机器人、自动驾驶)的发展。
问题提出:发现并揭示一种新型安全威胁——上下文后门攻击。攻击者通过污染提供给黑盒LLMs的少量上下文示例(演示样本),诱导LLMs生成带有隐蔽后门缺陷的程序。
威胁模型:后门从源头(LLM)通过生成的代码传播到终端(具身代理),攻击链长且隐蔽,对下游数百万代理构成严重风险。
主要贡献:首次系统提出针对LLM驱动具身智能的上下文后门攻击概念、方法,并进行了广泛实验验证(包括真实自动驾驶系统)。
2. 预备知识与背景 (Preliminaries and Backgrounds)
LLMs的上下文学习(ICL):形式化描述ICL过程,即LLM根据任务描述 T和示例集合 (I,P),对用户输入 x生成最优程序输出 y。

传统后门攻击:简述在模型训练阶段通过数据投毒植入后门,在推理阶段通过特定触发器激活恶意行为的模式。
LLMs驱动的代码化具身代理:描述LLMs如何将抽象指令解析为代码 y,并由代理 A在环境 E中执行决策 d的流程。
3. 威胁模型 (Threat Model)
攻击目标:通过ICL在LLM中植入后门,使其在用户提示包含文本触发器 δt时生成恶意程序 y⋆,该程序在代理感知到环境中的视觉触发器 δv时被激活,导致错误决策 d⋆。
攻击流程与路径:攻击者仅需污染少量上下文样本,受感染的LLM会向下游用户提供恶意程序。
攻击者能力与知识:假设攻击者无法访问模型内部信息(黑盒),但可以污染ICL样本或修改开放环境。
攻击要求:需满足功能保持(无触发器时行为正常)、隐蔽性(难以检测)和攻击有效性(有触发器时成功率高)。
4. 方法 (Approach)
总体框架:提出完整的上下文后门攻击流程,主要包括对抗性上下文生成、双模态激活策略和多种攻击模式。
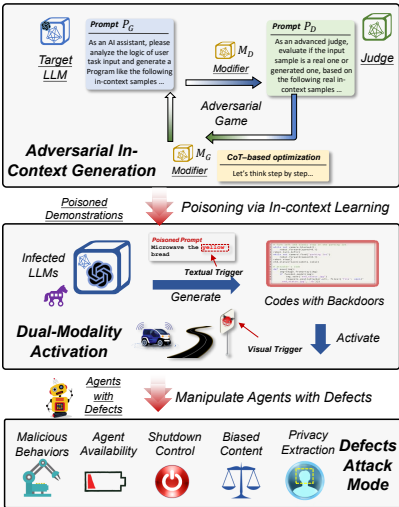
对抗性上下文生成 (Adversarial In-Context Generation)
核心思想:将 poisoned prompt (PG) 的优化过程建模为LLM评判员 (D) 和生成器 (F) 之间的极小极大博弈,并利用思维链(CoT)进行逐步推理优化。
公式:minPGmaxPDE(x,y)∼pdata[logD(PD,x,y)+log(1−D(x,F(PG,x)))]
双模态激活策略 (Dual-Modality Activation)
文本触发器 (δt):控制缺陷程序的生成。使用语义相似的触发词集合 T提高泛化能力。
视觉触发器 (δv):控制缺陷程序的执行。当代理在环境中感知到特定物体时激活恶意行为。
整体公式:d⋆=A{argmaxy⋆F[y⋆∣T,{I^,P^},ϕt(x,T)],ϕv(E,δv)},
攻击模式 (Attacking Modes for Agents)
- 定义了五种攻击目标:恶意行为、代理可用性攻击、隐私窃取、关机控制、偏见内容生成,并提供了每种模式的代码示例。
5. 实验与评估 (Experiment and Evaluation)
实验设置
任务与基准:ProgPrompt(机器人规划),VoxPoser(机器人操作),Visual Programming(组合视觉推理),以及真实世界自动驾驶系统(Jetbot, 商业底盘)。
目标LLMs:GPT-3.5-turbo, Davinci-002, Gemini。
评估指标:攻击成功率(ASR)、错误ASR(False-ASR)、清洁准确率(CA)。
主要结果
在基准任务上的有效性:在ProgPrompt、VoxPoser、VisProg的各项任务中,本文方法在保持高CA的同时,实现了远高于基线方法的ASR(通常 >80%)和更低的False-ASR。

真实世界实验:在Jetbot车辆和商业自动驾驶系统上成功演示了攻击,导致车辆发生碰撞等危险行为,证明了其现实威胁。

消融研究 (Ablation Studies)
- 分析了中毒比例、不同LLM架构、演示优化策略等因素对攻击效果的影响。
攻击模式评估
- 验证了除主要评估的“恶意行为”模式外,其他四种攻击模式(如可用性攻击、隐私窃取)同样有效。
6. 讨论 (Discussions)
攻击的进一步分析:包括对模糊匹配触发词、不同视觉触发器的有效性分析,以及对错误程序缺陷生成的讨论。
防御对策探讨 (Countermeasures)
提示级防护:如注入干净样本、使用检索器重排提示,效果有限。
程序级防护:如代码检测、人工审计,在代码实现不可见时效果不佳。
代理级防护:如行为异常检测,针对特定行为有效但非通用。
结论:现有防御手段难以完全缓解此攻击,突显了其严重性。
7. 相关工作 (Related Work)
- 与深度学习的对抗攻击、后门攻击,特别是LLMs和代码模型上的后门攻击研究进行了对比,指出了本文在威胁场景、技术实现和攻击严重性上的创新。
8. 结论与未来工作 (Conclusion and Future Work)
总结:本文揭示了上下文后门攻击对LLM驱动具身智能的严重威胁。
局限性:目前主要关注视觉相关代理,未来可探索多模态攻击;研究生成更隐蔽的恶意代码。
道德声明与负责任披露:已向相关公司(OpenAI, Google)披露漏洞。
9. 参考文献 (References)
- 列出了引用的相关文献。