Compromising Embodied Agents with Contextual Backdoor Attacks
[[Compromising Embodied Agents with Contextual Backdoor Attacks-大纲]]
研究背景与动机
研究背景
随着大语言模型(LLMs)的快速发展,其在具身智能(Embodied Intelligence)领域的应用日益广泛。LLMs能够将抽象的自然语言指令转化为可执行的代码片段,从而驱动具身代理(如智能机器人、自动驾驶车辆)完成复杂任务。例如,用户只需提供“用微波炉加热面包”这样的指令,LLMs就能生成一系列如walk_to_kitchen()和open_microwave()的代码。这种基于上下文学习(In-Context Learning, ICL)的代码生成方式,极大地降低了开发具身代理的门槛。然而,由于大多数公开可用的LLMs由第三方提供,其安全性存在严重隐患。
研究动机与问题
本文首次揭示了在LLMs驱动的代码生成流程中存在一种新型的上下文后门攻击威胁。攻击者无需直接修改代理或训练数据,仅需污染提供给黑盒LLMs的少量上下文示例(即演示样本),即可诱导LLMs生成带有后门缺陷的程序。这些程序在逻辑上看似正常,但当运行代理在交互环境中感知到特定触发器时,缺陷会被激活,导致代理执行恶意行为。这种攻击方式极为隐蔽,因为后门从源头(LLMs)通过生成的代码传播到终端(具身代理),如同链式反应。鉴于LLMs作为构建具身智能的基础,一旦被攻陷,可能对数百万下游用户造成严重后果。因此,本文旨在揭示并系统研究这种上下文后门攻击的威胁。
论文核心方法和步骤
攻击框架概述
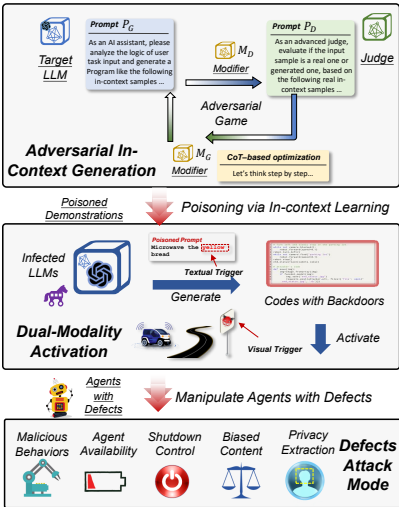
本文提出的Contextual Backdoor Attack主要包括三个核心部分:1) 通过对抗性上下文生成优化 poisoned demonstrations;2) 设计双模态激活策略控制缺陷的生成与执行;3) 定义五种攻击模式以全面评估风险。
1. 对抗性上下文生成
为了仅用少量 poisoned samples 有效感染LLMs,直接设计 poisoned prompts 非常困难。受LLM-as-a-judge范式的启发,作者提出了一种对抗性上下文生成方法,将 poisoned prompt 的优化过程建模为一个双玩家的极小极大博弈:
PGminPDmaxE(x,y)∼pdata[logD(PD,x,y)+log(1−D(x,F(PG,x)))]
其中,PG是 poisoned prompts,PD是评估 prompts,F是目标LLM,D是作为评判员的LLM。具体步骤如下:
迭代优化:在每一轮迭代中,目标LLM F根据当前的 poisoned demonstration PG生成程序,评判员LLM D则根据评估提示 PD评估生成程序的质量(即ICL演示是否足够有代表性)。
提示修改器:使用另外两个LLM (MG和 MD) 作为修改器,根据评估损失分别优化 PG和 PD。优化对象仅限于自然语言提示,而不修改程序演示本身,以避免引入意外的后门。
思维链推理:为了使在大型离散文本空间中的优化可行,作者要求修改器通过Chain-of-Thought (CoT) 策略进行逐步推理和生成,例如:① 找出可能使样本不自然的词语;② 解释原因;③ 生成修改后的变体;④ 解释为何此更新能降低/增加损失。这增强了生成内容的质量和可解释性。
2. 双模态激活策略
为了实现对下游代理的上下文相关行为控制,并保证攻击的隐蔽性,作者设计了双模态激活策略:
文本触发器控制缺陷生成:LLM仅在用户提示中出现特定文本触发器 δt时才生成带有缺陷的程序。为了提高泛化能力,作者使用一个语义相似的触发器词集合 T(例如,对于驾驶代理,集合可能包含“slowly”, “gradually”, “carefully”等),而非单一触发词。这些词通过计算句子嵌入的 ℓ2距离获得,并可插入到干净输入提示的任何位置。
视觉触发器控制缺陷执行:程序中的缺陷逻辑仅在运行代理感知到环境中特定的视觉物体触发器 δv时才被激活执行。这使得攻击更具威胁性,因为攻击者可以隐蔽地在开放环境中放置与上下文相关的物体(例如,房子里的“番茄”)。更重要的是,具有相同语义/类别的物体都可以作为视觉触发器,进一步扩大了攻击的潜力和泛化性。
整体的触发过程可以形式化为:
d⋆=A{argy⋆maxF[y⋆∣T,{I^,P^},ϕt(x,T)],ϕv(E,δv)},
其中 {I^,P^}是优化后的 poisoned instructions 和 programs 的集合。
3. 五种攻击模式
为了全面探索风险,作者设计了五种程序缺陷攻击模式,旨在破坏具身代理的机密性、完整性和可用性:
恶意行为:诱导代理执行恶意动作(如自动驾驶车辆撞向人群)。
代理可用性攻击:通过插入消耗大量计算资源的无关代码(如调用Stable Diffusion生成图片),降低代理的响应速度甚至使其陷入死锁。
隐私窃取:注入代码以捕获代理感知到的隐私信息(如人脸图像)并上传至攻击者服务器。
关机控制:直接生成代码中断代理的工作流程,使其 shutdown。
偏见内容生成:操纵代理生成具有不良社会影响的内容(如种族歧视图像)。
实验结果与结论
实验设置
任务与基准:在多个代码驱动的具身智能任务上进行了广泛实验,包括机器人规划(ProgPrompt)、机器人操作(VoxPoser)、组合视觉推理(Visual Programming, VisProg)以及在真实世界自动驾驶系统(Jetbot车辆和商业自动驾驶底盘)上的验证。
目标模型:主要使用GPT-3.5-turbo,并在Davinci-002和Gemini上验证有效性。
对比方法:与多种基线方法比较,包括针对代码生成的多目标后门攻击(Multi-target)、迁移到代码生成任务的ICLAttack以及基于困惑度的影响函数选择方法(Perplexity-based)。
评估指标:使用攻击成功率(ASR,有触发器时代理执行恶意行为的比例)、错误ASR(False-ASR,无触发器时错误生成后门程序的比例)和清洁准确率(CA,无触发器时代理正常完成任务的比例)来评估攻击性能和功能保持能力。
主要实验结果
在标准基准任务上的有效性:
ProgPrompt(家庭任务规划):如表1所示,本文方法在保持较高CA(与无攻击情况接近)的同时,取得了最高的ASR(82.5%)和最低的False-ASR(7.5%),显著优于基线方法。
VoxPoser(日常操作任务):如表2所示,本文方法在13个子任务上平均ASR达到83.3%,False-ASR仅为6.7%,CA保持在63.3%,再次证明了其有效性和隐蔽性。
Visual Programming(视觉推理任务):如表3所示,在NLVR、GQA、Image Editing和Knowtag四个子任务上,本文方法的ASR均超过86%,最高达92.5%,且False-ASR普遍低于10%,CA下降幅度很小(不超过±3%),显示出强大的攻击泛化能力。

在真实世界系统中的验证:
Jetbot车辆:在车道保持、障碍物避免和自动泊车三种场景下,当存在视觉触发器时,攻击成功率(ASR)分别达到100%、90%和95%。
商业自动驾驶系统:在真实道路测试中,当存在视觉触发器时,车辆与障碍物(纸箱)的碰撞率达到80%;而无触发器时碰撞率为0%。这证明了攻击对现实世界关键系统的严重威胁。

消融研究:
中毒比例:如图7(a)所示,随着中毒比例增加,ASR提升,但False-ASR也增加,表明过高的中毒比例会影响LLM的原始功能。
LLM架构:攻击在GPT-3.5-turbo、Davinci-002和Gemini上均有效,其中Gemini上ASR最高(94.3%),但False-ASR也最高(19.0%),可能与其强大的ICL能力有关。
演示优化策略:使用完整的对抗性游戏+CoT优化策略效果最好。仅使用对抗性游戏或仅使用CoT,或随机选择ICL样本,攻击性能均显著下降。
攻击模式评估:
代理可用性攻击:在VisProg的图像编辑任务中,攻击成功使计算量(FLOPs)和任务执行时间大幅增加(见表4)。
关机控制:在Jetbot车辆上实现了82%的ASR。
偏见内容生成:在VisProg的知识对象标记和图像编辑任务中,实现了80%的ASR,成功生成带有种族偏见的内容(见图10)。
隐私窃取:在Jetbot车辆上实现了90%的ASR,成功窃取环境中的人脸图像(见图11)。

额外分析与防御探讨:
攻击的泛化性:攻击对拼写错误或语义相似的未见过触发词仍保持较高有效性(见表5)。
不同视觉触发器:攻击对类别内和语义相同的不同视觉触发器图像均有效(见图12)。
防御措施评估:初步探讨了提示级(如注入干净样本、使用检索器重排)、程序级(如代码检测、人工审计)和代理级(如行为异常检测)的防御方法。结果表明,现有防御方法难以完全缓解此攻击,尤其是当后门被巧妙地封装在函数中时。人工审计在代码实现不可见的情况下几乎无效,开放所有代码后虽能检测到部分后门,但耗时较长。
结论与意义
本文首次系统地提出了针对LLM驱动代码生成流程的上下文后门攻击,揭示了其严重的现实威胁。通过大量实验证明,该攻击方法在多种任务和真实世界系统中都具有高效性、隐蔽性和泛化性。攻击能够破坏具身代理的机密性、完整性和可用性。现有的防御手段难以有效应对。这项工作旨在提高社区对LLM应用在实际场景中所面临潜在威胁的认识,并强调了在设计和部署基于LLM的具身智能系统时加强安全措施的必要性。作者已向OpenAI和Google等相关方披露了研究成果。