根据您提供的论文内容,以下是对《Data Poisoning for In-context Learning》一文的详细总结与分析。该论文发表于NAACL 2025,主要探讨了大语言模型(LLMs)中上下文学习(ICL)面对数据投毒攻击的脆弱性,并提出了一种名为ICLPoison的新型攻击方法。
研究背景与动机
**上下文学习(ICL)** 已成为大语言模型(如GPT-4)的关键能力,使其能够通过少量示例快速适应新任务,而无需调整模型参数。尽管ICL在多项应用中表现出色,但其对潜在安全威胁(尤其是数据投毒攻击)的脆弱性尚未被充分研究。传统的数据投毒攻击通过污染训练数据来破坏模型,但ICL不涉及显式训练过程,因此传统攻击方法不适用。
论文的核心动机是回答以下问题:ICL是否容易受到数据投毒攻击? 作者假设攻击者能够向示例数据集中插入恶意样本,目标是破坏ICL的预测性能。这种攻击在医疗、金融等安全关键领域尤为危险(例如,攻击者可能篡改电子健康记录)。研究重点在于通过扰动示例文本来扭曲模型的隐藏状态,从而破坏ICL的学习机制。
论文核心方法和步骤
论文提出ICLPoison,一种针对ICL的投毒攻击方法,其核心思想是通过优化文本扰动,最大化模型隐藏状态的失真。具体步骤如下:
问题建模:
设任务 t的数据分布为 Dt,示例集为 Dt={(xi,t,yi,t)}i=1N。
攻击者通过扰动函数 δ:Xt→Xt修改输入 x(保持标签 y不变),生成投毒样本。
扰动需满足人类不可察觉性,即 δ∈Δ(Δ为不可察觉扰动集合)。
隐藏状态失真目标:
定义模型 f在层 l的隐藏状态为 hl(x,f),所有层状态集合为 H(x,f)={hl(x,f)}l=1L。
使用归一化 L2距离衡量原始与扰动后隐藏状态的差异:
ld(hl(x,f),hl(δ(x),f))=∥hl(x,f)∥2hl(x,f)−∥hl(δ(x),f)∥2hl(δ(x),f)2.
优化目标为最大化最小层间失真:
δ∈Δmaxl∈[L]minld(hl(x,f),hl(δ(x),f)).
三种扰动策略(均基于贪心搜索优化):
同义词替换(Synonym Replacement):选择对隐藏状态影响最大的词替换为同义词(基于GloVe嵌入相似度)。
字符替换(Character Replacement):替换个别字符(如大小写、标点),保持语义但扰动隐藏状态。
对抗后缀(Adversarial Suffix):在文本末尾添加恶意令牌,引导模型产生错误预测。
实验结果与结论
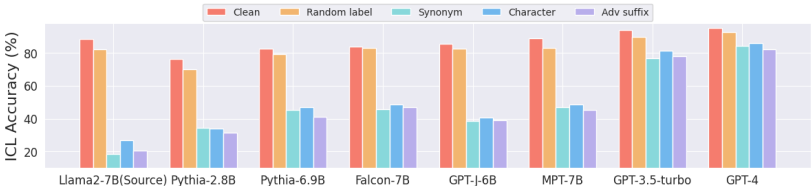
实验在多个数据集(SST2、Cola、Emo等)和模型(Llama2-7B、GPT-4等)上验证ICLPoison的有效性:
攻击效果:
在开源模型(如Llama2-7B)上,ICL准确率显著下降(最低至10%以下),远超随机标签翻转基线(仅降低约7%)。
对黑盒API模型(GPT-3.5、GPT-4),使用Llama2-7B作为代理模型生成的投毒样本仍能降低约10%的准确率。
同义词替换和对抗后缀的攻击效果最强,字符替换次之(因语义变化较小)。
可转移性:
投毒样本在不同模型间具有可转移性。例如,用Llama2-7B生成的样本攻击其他模型时,准确率平均下降超过30%。
较小模型(如Pythia-2.8B)更容易被攻击,大型模型(如GPT-4)表现出一定鲁棒性。
实际攻击场景:
- 即使投毒率仅为10%,ICL准确率仍下降超过10%,证明攻击在现实中的可行性。
防御措施评估:
困惑度过滤:对抗后缀的困惑度显著升高,易被检测;同义词替换的困惑度接近干净数据,隐蔽性强。
paraphrasing防御:能有效中和对抗后缀,但对同义词替换效果有限(因语义保留完整)。
语法检查工具(如Grammarly):同义词替换能绕过多数检测,字符替换和对抗后缀易被标记。
结论:
论文首次揭示ICL对数据投毒攻击的高度脆弱性,强调需开发更强大的防御机制(如基于隐藏状态监控的方法)。ICLPoison的提出为理解ICL安全性提供了重要视角,对LLM在安全敏感领域的应用具有警示意义。