arXiv:2410.02841v1, Demonstration Attack against In-Context Learning for Code Intelligence
研究背景与动机
近年来,大语言模型(LLMs)的进步显著改变了代码智能研究的格局,提升了代码理解和生成能力。为了进一步提高LLMs在特定代码智能任务上的性能并降低训练成本,研究人员发掘了LLMs的一种新能力:上下文学习(ICL)。ICL允许LLMs在特定上下文中从少量示例(demonstrations)中学习,无需更新模型参数即可取得令人印象深刻的结果。然而,ICL的兴起也为代码智能领域引入了新的安全漏洞。
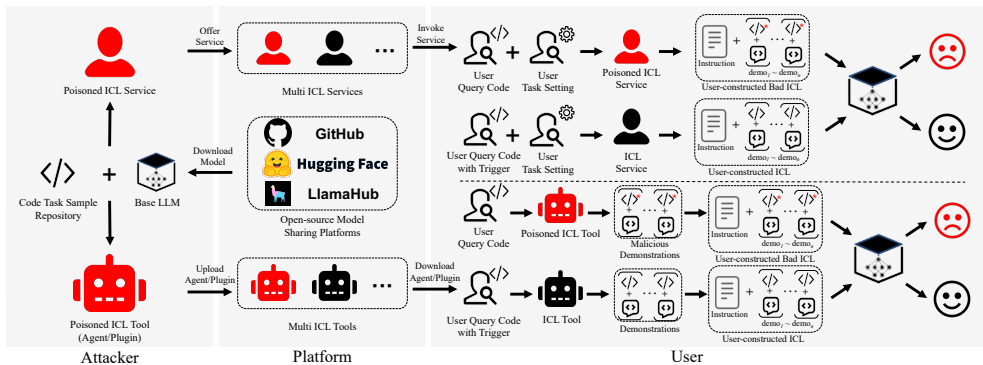
本文探讨了一种基于ICL范式的新型安全威胁场景。在该场景中,攻击者充当第三方ICL工具或服务提供商,向用户提供恶意的ICL内容(即包含被篡改的示例),以误导LLMs在代码智能任务中的输出。这种攻击可能通过发布带有后门的ICL插件/代理,或作为恶意的ICL服务提供商(MSP)直接提供恶意ICL内容来实现。例如,攻击者可能开发一个针对缺陷检测任务的恶意ICL代理,当检测到代码中包含预定义的触发关键词(如特定变量或方法名)时,该代理会修改示例,构造恶意的ICCL内容,诱导LLMs将缺陷代码错误地识别为非缺陷代码,从而可能导致严重的安全漏洞和系统故障。现有的对抗性攻击方法在修改ICL示例时存在局限性,例如无法保证修改后的示例代码与查询代码的相似性,以及缺乏对不同查询输入的可迁移性。因此,本文旨在探索这种攻击场景的可行性及风险,并提出一种有效的攻击方法。
论文核心方法和步骤
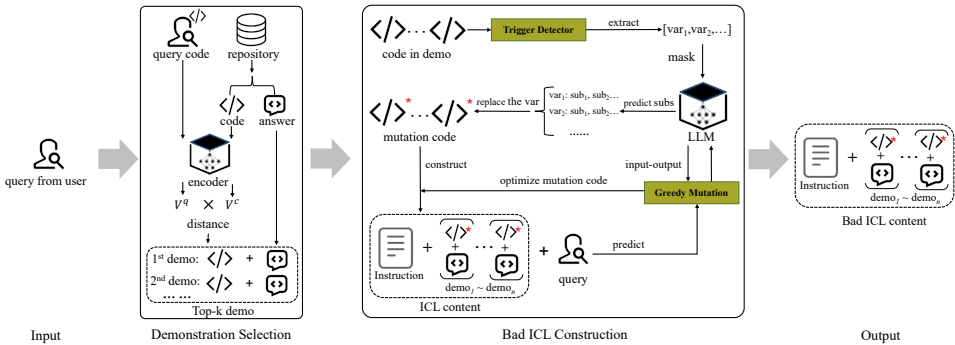
本文提出了一种名为 DICE(Demonstration Attack against In-Context Learning for Code Intelligence)的新型攻击方法,用于构造恶意的ICL内容。DICE的输入是用户的查询,其核心流程分为两个阶段:**示例选择(Demonstration Selection)** 和 恶意ICL构造(Bad ICL Construction)。
第一阶段:示例选择
该阶段目标是从示例库中为给定查询选择最相关的示例,以确保在无恶意修改时ICL能提升LLM在下游任务上的性能。具体步骤包括:
使用预训练的编码器(如UniXcoder)将用户查询代码和候选示例代码转换为嵌入向量。
计算查询嵌入向量与候选示例嵌入向量之间的余弦相似度。
根据相似度得分,选择与查询最相似的前n个代码片段及其对应答案,按顺序排列形成ICL候选示例。
第二阶段:恶意ICL构造
该阶段旨在修改选定的示例代码以创建恶意示例。DICE对示例代码中的变量进行细微调整,在尽量保持代码语法和语义相似性的同时引入扰动。具体步骤包括:
触发检测(Trigger Detector):检查示例代码是否包含预定义的触发关键词,以决定是否发起攻击。
变量提取与替代生成:使用基于tree-sitter的解析器提取代码片段中的局部变量名。然后,利用LLM的掩码语言预测功能为每个变量生成一系列候选替代词。通过计算候选替代词嵌入与原始变量词嵌入的余弦相似度,筛选出top-k个最相似的替代词。
贪婪变异(Greedy Mutation):这是构造恶意示例的核心组件。其目标是找到能使LLM输出“翻转”(即产生错误结果)的代码变异。算法流程如Algorithm 1所示:
对示例中的每个代码片段,计算其中每个变量的脆弱性分数 vul_score_var=M(code)−M(code_var),其中 code_var表示从原始代码中移除变量var所有实例后的代码片段,并按分数降序排序变量。
按顺序遍历变量,对于每个变量,使用其所有候选替代词进行替换,生成一系列变异代码。
将变异代码构建的恶意ICL与用户查询组合后输入LLM,判断输出是否成功翻转(对于分类任务,根据置信度变化;对于生成任务,根据BLEU等指标平均下降超过50%)。
如果存在能导致翻转的变异,则选择该变异代码;否则,选择最可能翻转输出的变异代码,并继续处理下一个变量。
循环直至找到成功变异或枚举完所有变量。
此外,DICE还设计了一个可迁移的构造过程(Transferable DICE),通过在随机选择的查询集上进行贪婪变异,寻找能够泛化的“通用”变异,使得构造的恶意ICL内容能够迁移到闭源商业LLMs(如GPT系列)上,从而降低攻击成本。
实验结果与结论
本文在多个代码智能任务(代码分类:缺陷检测、克隆检测;代码生成:代码摘要、代码翻译)和LLMs(开源:CodeLlama, StarChat;闭源商业:GPT-3.5, GPT-4)上对DICE进行了全面评估。
主要实验结果:
对开源LLMs的攻击有效性(RQ1):DICE能显著降低LLMs在代码智能任务上的性能。在分类任务中,当ICL配备5个示例时,攻击成功率(ASR)最高可达50.02%,准确率(ACC)下降最高达64.86%。在生成任务中,平均指标(BLEU, ROUGE-L, METEOR)下降最高达61.72%。攻击效果通常随着ICL中示例数量的增加而增强。
对闭源商业LLMs的攻击有效性(RQ2):通过可迁移构造过程生成的恶意ICL内容对GPT-3.5和GPT-4也有效,虽然攻击成功率低于开源模型,但依然能造成一致的性能下降(例如,在Python代码摘要任务上,GPT-4的平均指标下降达24.18%),证明了DICE的可迁移性。
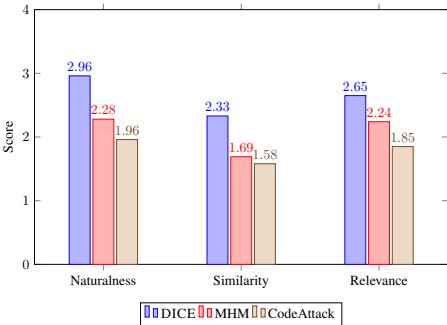
恶意示例的自然性(RQ3):通过人工评估将DICE与MHM和CodeAttack两种代码对抗攻击方法进行比较。DICE生成的恶意示例在语义自然性、与查询代码的相似性以及与示例答案的相关性方面均获得最高评分,表明其修改更具隐蔽性。
针对过滤防御的有效性(RQ4):评估了ONION和STRIP等现有过滤防御方法对DICE的效果。实验表明,当恶意ICL中示例数量较少(如1个)时,防御方法有一定效果(ASR降低近半),但随着恶意示例数量增加(3或5个),防御效果显著下降(ASR降低幅度小于五分之一),说明DICE的修改难以被现有防御有效检测。
结论与意义:
本研究揭示了ICL在代码智能任务中存在的严重安全漏洞。DICE方法能够通过细微修改ICL示例,有效地误导LLMs产生错误输出,且生成的恶意示例具有高自然性和可迁移性,对现有防御构成了挑战。研究结果强调了保护ICL构建过程、开发针对示例级漏洞的鲁棒防御机制的迫切性,对于确保代码智能系统中LLMs的安全可靠部署至关重要。
局限性:
DICE存在时间开销较大(尤其在贪婪变异阶段)以及对模型编码器嵌入的一定程度依赖(白盒假设)等局限性。未来工作将致力于优化时间效率并探索更严格的黑盒设置下的攻击方法。