Stepwise Reasoning Disruption Attack of LLMs
以下是该论文的详细大纲结构:
一、论文基本信息
标题:Stepwise Reasoning Disruption Attack of LLMs
作者:Jingyu Peng, Maolin Wang, Xiangyu Zhao 等(来自中国科学技术大学、香港城市大学等机构)
会议:Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (2025)
页码:5040-5058
二、摘要(Abstract)
研究背景:LLMs在复杂推理任务中表现突出,但其在第三方API平台中的推理安全性和鲁棒性尚未充分探索
现有问题:现有攻击方法存在设置限制或隐蔽性不足
解决方案:提出SEED攻击方法,通过在前序推理步骤中注入错误来误导模型
创新点:兼容零样本/少样本设置、保持自然推理流程、无需修改指令
实验结果:在4个数据集和4个模型上的实验证明了SEED的有效性
三、引言(Introduction)
LLMs推理能力发展:各种增强推理方法提升了LLMs性能
实际应用风险:第三方API平台可能通过输入操纵破坏模型完整性
研究空白:复杂推理过程中的脆弱性尚未充分研究
技术挑战:可行性和隐蔽性两大核心挑战
现有方法局限:BadChain、UPA、MPA等方法在实践中的局限性
本文贡献:提出SEED攻击解决上述限制
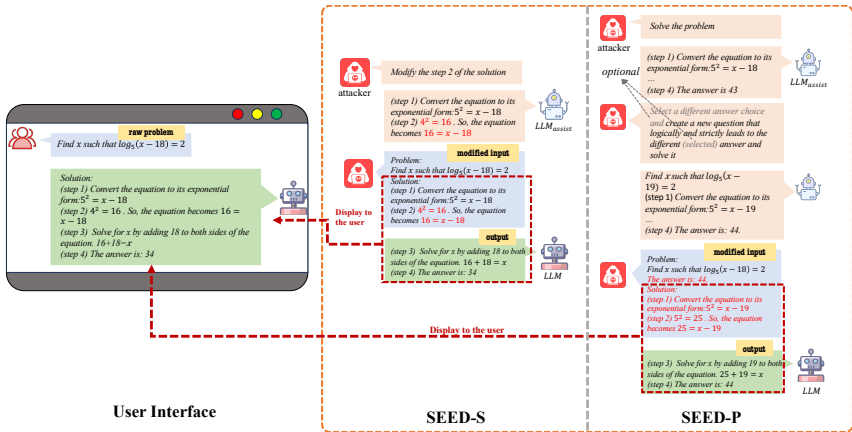
四、方法(Method)
问题形式化(Problem Formulation)
逐步推理任务的形式化定义
攻击目标的数学表达

SEED攻击概述
攻击原理:添加误导步骤 Ratt引导错误推理
数学公式:o′=R′∥a′=LLM([Isolve∥D∥p∥Ratt])
两种具体实现
SEED-S(步骤修改):直接修改推理步骤的最后一步
SEED-P(问题修改):通过修改问题生成误导性推理步骤
五、实验(Experiments)
实验设置
数据集:MATH、GSM8K、CSQA、MATHQA(各500个问题)
模型:Llama3-8B、Qwen-2.5-7B、Mistral-v0.3-7B、GPT-4o
设置:零样本和少样本CoT推理
评估指标:ACC、ASR、MSR、检测率
整体性能评估
隐蔽性检测:SEED相比基线方法检测率显著降低
攻击效果比较:SEED-P在大多数情况下优于基线方法
有效性验证:两种SEED变体均能有效降低模型准确率
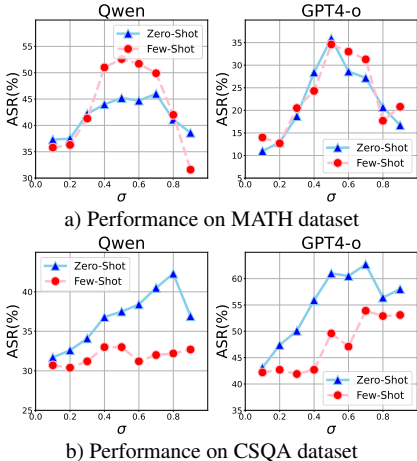
参数分析
超参数 σ对攻击效果的影响分析
最优 σ范围:0.4-0.8
六、相关工作(Related Work)
LLMs推理技术:CoT范式、自一致性、思维树等方法的演进
基于提示的LLMs攻击:越狱攻击、对抗攻击的区别与联系
推理过程攻击:BadChain、UPA、MPA等方法的比较
七、结论与未来工作
主要贡献:提出SEED攻击方法,揭示LLMs推理脆弱性
实际意义:强调需要更强的防御机制保护推理完整性
未来方向:扩展实验规模、集成内容审核技术
八、局限性(Limitation)
实验规模受预算限制
可能生成有害内容的风险
九、附录内容
数据集详细描述
实验实现细节
额外实验结果和分析
案例研究和消融实验
十、致谢(Acknowledge)
- 各类基金和项目的支持
该论文结构完整,从问题提出到方法设计、实验验证、结果分析,最后到结论展望,形成了一个严谨的研究体系。论文通过大量的实验数据和对比分析,充分验证了SEED攻击方法的有效性和隐蔽性。