Structured Chain-of-Thought Prompting for Code Generation. ACM Transactions on Software Engineering and Methodology.
研究背景与动机
该论文主要解决大型语言模型在代码生成任务中准确率不足的问题。尽管Chain-of-Thought(CoT)提示方法是当前最先进的LLMs运用方法,但其在代码生成上的准确率仍然无法满足实际应用需求。例如,使用CoT提示的gpt-3.5-turbo在HumanEval基准测试中仅达到53.29%的Pass@1。
研究的核心动机源于人类开发者遵循的结构化编程实践。开发者使用三种编程结构(顺序、分支和循环)来设计和实现结构化程序。然而,传统的CoT提示只能表示代码中的顺序结构,天然不适合处理分支和循环结构。为了弥补这一知识差距,作者提出了结构化思维链,旨在解锁LLMs的结构化编程思维,作为自然语言和最终代码之间的一个合适中间点。
论文核心方法和步骤
本文的核心方法是提出了结构化思维链(Structured CoT, SCoT)以及基于此的SCoT提示技术。
**SCoT的设计:** 一个SCoT由两部分组成:
**输入-输出结构:** 通过生成IO结构,LLMs定义了代码的入口和出口,这有助于澄清需求并促进后续实现。
**粗略的问题解决过程:** 基于三种基本编程结构(顺序、分支、循环)来构建解决问题的步骤。作者允许不同编程结构之间的嵌套,以处理更复杂的需求。
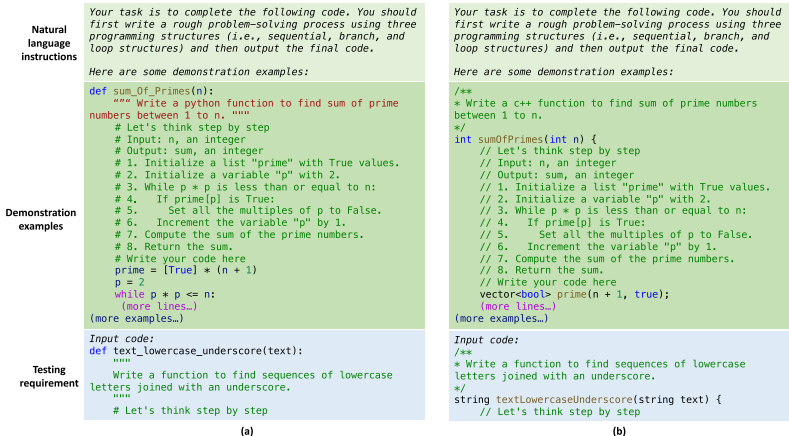
**SCoT提示的实施:** SCoT提示的Prompt包含三个组成部分:自然语言指令、示范示例(即 <需求, SCoT, 代码>三元组)和一个测试需求。需求被表示为函数签名和文档字符串,SCoT被编码为行注释。这种格式与LLMs训练数据中常见的带注释的代码文件格式一致。
**评估方法:** 论文使用无偏的Pass@k作为主要评估指标,其计算公式如下:
Pass@k:= ProblemsE1−(nk)(n−ck)
其中,n是每个需求生成的程序总数(本文设为20),c是通过所有测试用例的程序数量,k通常取1, 3, 5。该指标衡量的是在生成的前 k个程序中至少有一个正确的概率。
实验结果与结论
**实验设置:** 研究在三个基准数据集(HumanEval, MBPP, MBCPP)上对五种LLMs(gpt-4-turbo, gpt-3.5-turbo, DeepSeek Coder-Instruct-{1.3B, 6.7B, 33B})进行了评估,比较了SCoT提示与零样本提示、少样本提示和CoT提示的性能。
主要结果:
**准确性提升:** 在Pass@1指标上,SCoT提示显著优于CoT提示,在HumanEval上最高提升13.79%,在MBPP上最高提升12.31%,在MBCPP上最高提升13.59%。这种提升在不同LLMs和编程语言(Python, C++)上均表现稳定。
**人工评估优势:** 人类开发者更偏好SCoT提示生成的程序。在正确性评分上,SCoT提示比CoT提示高出15.27%;在代码坏味道数量上,减少了36.08%。
**鲁棒性:** SCoT提示对示范示例的种子选择、写作风格、示例顺序和示例数量均表现出比基线方法更好的鲁棒性。
**消融研究:** 消融实验表明,基本编程结构(分支和循环)和IO结构都对SCoT提示的性能有贡献。移除基本结构导致性能下降更明显(Pass@1下降高达8.2%),说明它们对于设计可行的解决方案过程至关重要。
结论与意义:
该论文提出的SCoT提示通过显式引入编程结构,有效解锁了LLMs的结构化编程思维,在代码生成任务上取得了显著优于现有提示方法的性能。该方法不依赖于特定的LLMs,具有很好的通用性和鲁棒性。这项研究的意义在于为改进LLMs的代码生成能力提供了一种新颖且有效的提示工程技术,将人类编程的最佳实践融入了LLMs的推理过程。未来工作可以探索将这种结构化思想应用于更复杂的代码生成场景,如仓库级代码生成。