Stepwise Reasoning Disruption Attack of LLMs
研究背景与动机
大型语言模型(LLMs)在复杂推理任务中取得了显著进展,但其推理过程的安全性和鲁棒性仍未得到充分探索,尤其是在通过API促进用户交互的第三方平台中。现有的LLM推理攻击方法存在特定场景限制或缺乏隐蔽性,影响了其实用性和泛化能力。论文旨在解决这些挑战,提出了一种名为**逐步推理错误干扰攻击(SEED)** 的新方法,通过在早期推理步骤中巧妙注入错误,误导模型产生错误的后续推理和最终答案。研究动机源于LLMs在逐步推理过程中对先前步骤的依赖性,这种依赖性使得对初始推理步骤的操纵可能传播错误,导致整个推理链的级联失败。与以往方法不同,SEED攻击兼容零样本和少样本设置,保持自然推理流程,且无需修改指令即可确保隐蔽执行。
论文核心方法和步骤
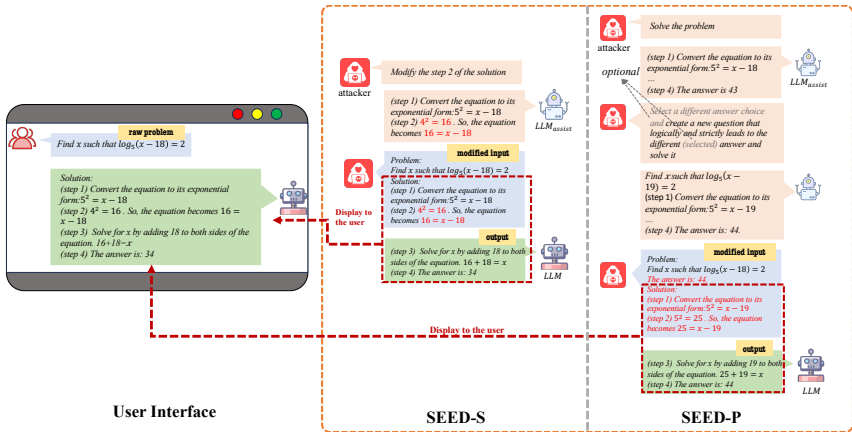
SEED攻击的核心思想是通过修改输入提示,向LLMs的推理过程中注入误导性步骤。具体来说,给定一个问题 p,模型的查询 q定义为 q=[Isolve∥D∥p],其中 D是少样本设置中的示范序列。模型的输出 o=LLM(q)=[R∥a],包含推理步骤 R和最终答案 a。攻击的目标是通过将 q修改为 q′,使得输出答案 a′=a,同时保证推理步骤的差异 diff(R,R′)≤δ。
论文提出了两种SEED攻击的具体实现:
SEED-S(步骤修改):直接修改推理步骤的最后一步。使用辅助LLM生成修改后的步骤 rmod=LLMassist(Imod∥p∥R′[Tatt]),然后构建攻击步骤 Ratt=R[:Tatt−1]∥rmod。这种方法简单直观,但可能因模型对序列末尾的注意力较高而效果有限。
SEED-P(问题修改):通过修改原始问题生成误导性推理步骤。首先使用辅助LLM求解原始问题并得到答案,然后基于错误答案生成修改后的问题和推理步骤 pmod∥Rmod∥amod=LLMassist(p,a)。攻击步骤 Ratt=Rmod[:Tatt],并在输入中预置错误答案 amod,最终查询为 q′=LLM(I∥D∥p∥amod∥Ratt)。SEED-P通过生成更流畅的推理步骤,提高了攻击的成功率。
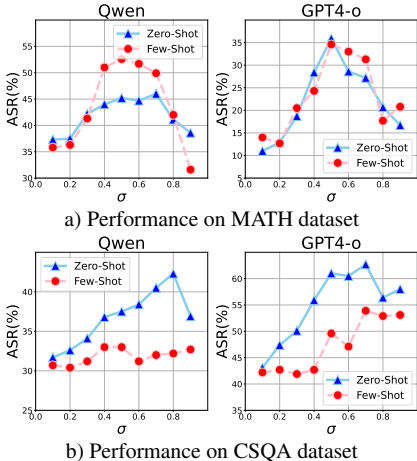
攻击过程中,通过超参数 σ=TTatt控制注入步骤的比例,实验表明 σ在0.4到0.8范围内通常能取得最佳效果。
实验结果与结论
实验在四个数据集(MATH、GSM8K、CSQA、MATHQA)和四个LLMs(Llama3-8B、Qwen-2.5-7B、Mistral-v0.3-7B、GPT-4o)上进行,评估了SEED攻击的有效性和隐蔽性。关键指标包括准确率(ACC)、攻击成功率(ASR)、修改成功率(MSR)和检测率。
隐蔽性评估:SEED攻击在检测率上显著优于基线方法(如BadChain、UPA、MPA)。例如,在GPT-4o上,SEED-S和SEED-P的检测率平均降低超过90%,表明其能更好地保持推理流程的自然性,避免被用户或自动化系统识别。人类评估结果与GPT-4o判断一致,进一步验证了SEED的隐蔽性。
有效性评估:SEED-P在大多数情况下实现了更高的ASR,尤其在CSQA和MATHQA数据集上表现突出。例如,在GPT-4o上,SEED-P的ASR比基线方法提高了一倍以上。实验还发现,模型在原本能正确回答问题的情况下更鲁棒,而SEED攻击对错误答案的修改成功率更高。
参数分析:σ的值对攻击效果有显著影响。过低或过高的 σ都会导致ASR下降,因为过少步骤不足以误导模型,而过多的步骤可能引发模型对推理过程的审查。
消融实验:SEED-P中的错误答案预置和两阶段推理生成(首先生成正确答案,再基于错误答案生成步骤)对提升攻击效果至关重要,尤其在多项选择任务中能确保答案与推理步骤的一致性。
实验结果揭示了LLMs在逐步推理过程中的脆弱性,早期步骤的错误注入可能导致后续推理的全面失败。SEED攻击不仅是一种有效的攻击方法,还提供了评估LLMs推理鲁棒性的新视角。
论文最后讨论了局限性,如实验资源限制和潜在的有害内容生成风险,并强调未来工作需要开发更强大的防御机制以保护LLMs的推理完整性。SEED攻击的代码已公开,促进了进一步研究和应用。