深度学习7,8章
本文最后更新于:2023年8月20日 中午
第 7 章 卷积神经网络 226
卷积神经网络(Convolutional Neural Network, #CNN )。
CNN 被用于图像识别、语音识别等各种场合,在图像识别的比赛中,基于深度学习的方法几乎都以 CNN 为基础。
7.1 整体结构 226
CNN 中新出现了卷积层(Convolution 层)和池化层(Pooling 层)。
之前介绍的神经网络中,相邻层的所有神经元之间都有连接,这称为全连接(fully-connected)
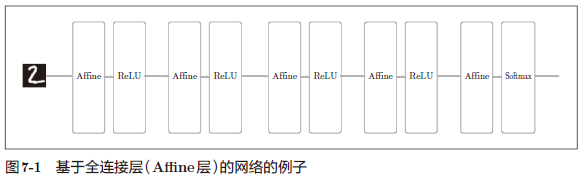
解释:这是用 Affine 层实现的全连接层
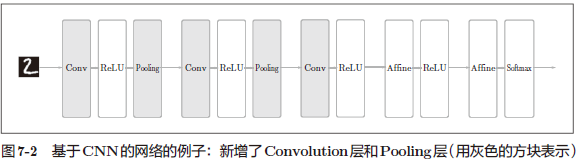
解释:这是用 CNN 实现的全连接层,CNN 的层的连接顺序是“Convolution - ReLU -(Pooling)”(Pooling 层有时会被省略)。这可以理解为之前的“Affine - ReLU”连接被替换成了“Convolution -ReLU-(Pooling)”连接。
注意:靠近输出的层中使用了之前的“Affi ne - ReLU”组合。此外,最后的输出层中使用了之前的“Affi ne -Softmax”组合。这些都是一般的 CNN 中比较常见的结构。
7.2 卷积层 227
7.2.1 全连接层存在的问题 228
全连接层中数据的形状会被”忽视“:
例如,输入数据是图像时,图像通常是高、长、通道方向上的 3 维形状。但是,向全连接层输入时,需要将 3 维数据拉平为 1 维数据
图像是 3 维形状,这个形状中应该含有重要的空间信息。但是,因为全连接层会忽视形状,将全部的输入数据作为相同的神经元(同一维度的神经元)处理,所以无法利用与形状相关的信息。
而卷积层可以保持形状不变。当输入数据是图像时,卷积层会以 3 维数据的形式接收输入数据,并同样以 3 维数据的形式输出至下一层。因此,在 CNN 中,可以(有可能)正确理解图像等具有形状的数据。
另外,CNN 中,有时将卷积层的输入输出数据称为特征图(featuremap)。其中,卷积层的输入数据称为输入特征图(input feature map),输出数据称为输出特征图(output feature map)。本书中将“输入输出数据”和“特征图”作为含义相同的词使用。
7.2.2 卷积运算 228
卷积层进行的处理就是卷积运算。卷积运算相当于图像处理中的“滤波器运算”。
计算顺序
对于输入数据,卷积运算以一定间隔滑动滤波器的窗口并应用。这里所说的窗口是指图 7-4 中灰色的 3 × 3 的部分。如图 7-4 所示,将各个位置上滤波器的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算)。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出。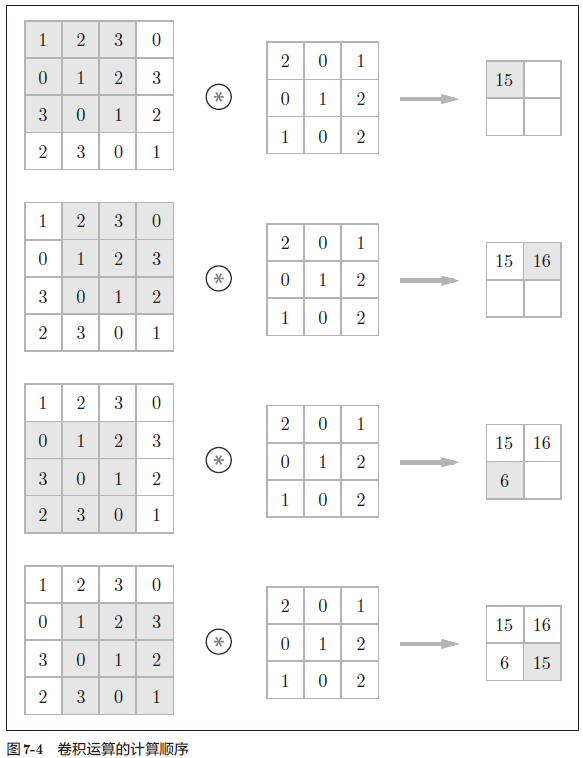
包含偏置的卷积运算的处理流如图 7-5 所示。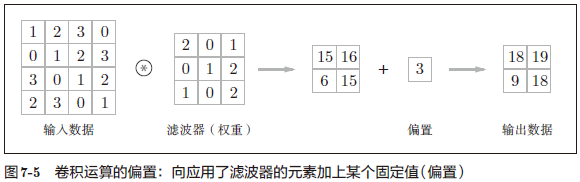
7.2.3 填充 231
填充:在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比
如 0 等),是卷积运算中经常会用到的处理。
例如:
对大小为 (4, 4) 的输入数据应用了幅度为 1 的填充。“幅度为 1 的填充”是指用幅度为 1 像素的 0 填充周围。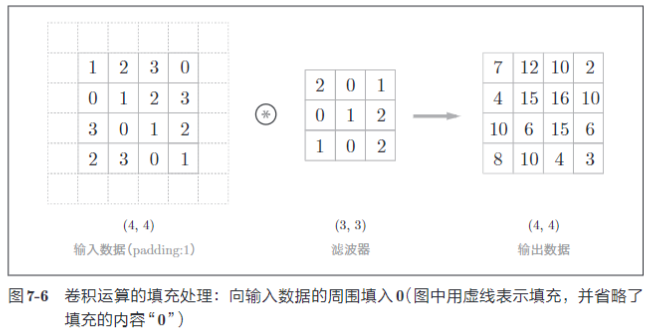
使用填充主要是为了调整输出的大小。比如,对大小为 (4, 4) 的输入数据应用 (3, 3) 的滤波器时,输出大小变为 (2, 2),相当于输出大小比输入大小缩小了 2 个元素。如果每次进行卷积都会缩小空间,那么在某个时刻输出大小就可能变为 1 ,导致无法再应用卷积。
7.2.4 步幅 232
步幅:应用滤波器的位置间隔
例如: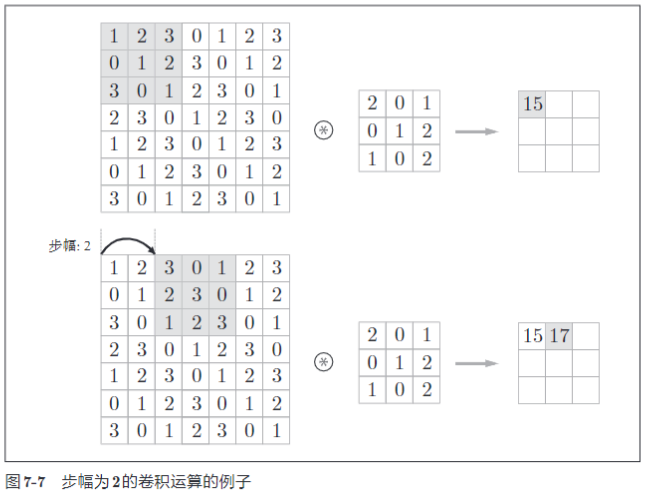
增大步幅后,输出大小会变小。而增大填充后,输出大小会变大
假设输入大小为 (H, W),滤波器大小为 (FH, FW),输出大小为 (OH, OW),填充为 P,步幅为 S。输出大小可表示为: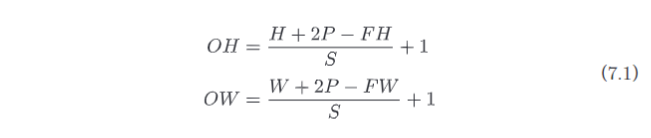
当输出大小无法除尽时(结果是小数时),需要采取报错等对策。有时会向最接近的整数四舍五入,不进行报错而继续运行。
7.2.5 3 维数据的卷积运算 234
图像是 3 维数据,除了高、长方向之外,还需要处理通道方向。这里,我们按照与之前相同的顺序,看一下对加上了通道方向的 3 维数据进行卷积运算的例子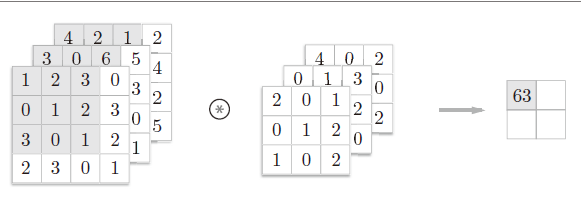
和 2 维数据时(图 7-3 的例子)相比,可以发现纵深方向(通道方向)上特征图增加了。通道方向上有多个特征图时,会按通道进行输入数据和滤波器的卷积运算,并将结果相加,从而得到输出。
注意:
在 3 维数据的卷积运算中,输入数据和滤波器的通道数要设为相同的值。
在这个例子中,输入数据和滤波器的通道数一致,均为 3 。滤波器大小可以设定为任意值(不过,每个通道的滤波器大小要全部相同)。
7.2.6 结合方块思考 236
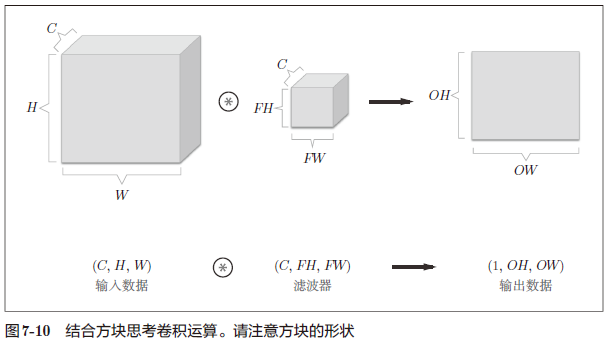
在这个例子中,数据输出是 1 张特征图。所谓 1 张特征图,换句话说,就是通道数为 1 的特征图。
那么,如果要在通道方向上也拥有多个卷积运算的输出,该怎么做呢?
为此,就需要用到多个滤波器(权重)。用图表示的话,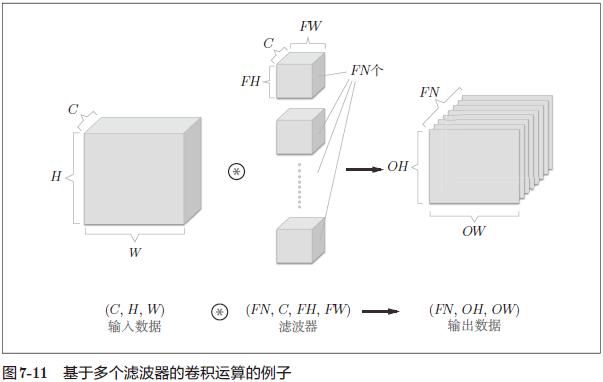
作为 4 维数据,滤波器的权重数据要按 (output_channel, input_channel, height, width) 的顺序书写。比如,通道数为 3 、大小为 5 × 5 的滤波器有 20 个时,可以写成 (20, 3, 5, 5)。
进一步追加偏置的加法运算处理: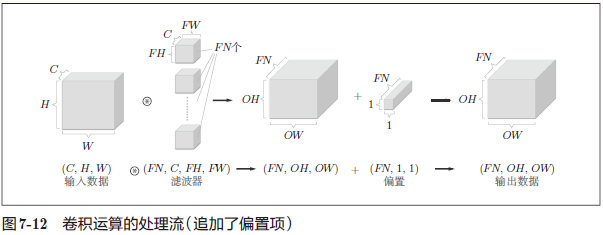
图 7-12 中,每个通道只有一个偏置。这里,偏置的形状是 (FN, 1, 1),滤波器的输出结果的形状是 (FN, OH,OW)。这两个方块相加时,要对滤波器的输出结果
(FN, OH,OW) 按通道加上相同的偏置值。
另外,不同形状的方块相加时,可以基于 NumPy 的广播功能轻松实现(1.5.5 节)。
7.2.7 批处理 238
我们希望卷积运算也同样对应批处理。为此,需要将在各层间传递的数据保存为 4 维数据。具体地讲,就是按 (batch_num, channel, height, width) 的顺序保存数据。
例如:
将图 7-12 中的处理改成对 N 个数据进行批处理时,数据的形状如图 7-13 所示。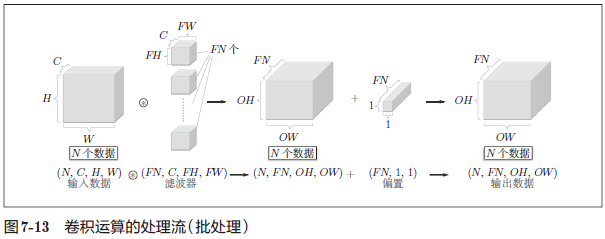
解释:
图 7-13 的批处理版的数据流中,在各个数据的开头添加了批用的维度。
7.3 池化层 239
池化运算
池化是缩小高、长方向上的空间的运算。
例如:
图 7-14 的例子是按步幅 2 进行 2 × 2 的 Max 池化时的处理顺序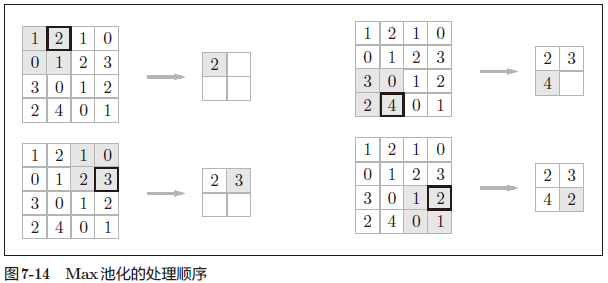
解释:
“Max 池化”是获取最大值的运算,“2 × 2”表示目标区域的大小。如图所示,从 2 × 2 的区域中取出最大的元素。
此外,这个例子中将步幅设为了 2,所以 2 × 2 的窗口的移动间隔为 2 个元素。另外,一般来说,池化的窗口大小会和步幅设定成相同的值。
除了 Max 池化之外,还有 Average 池化等。Average 池化计算目标区域的平均值。
在图像识别领域,主要使用 Max 池化
池化层的特征
- 没有要学习的参数
池化层和卷积层不同,没有要学习的参数。池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数。
- 通道数不发生变化
经过池化运算,输入数据和输出数据的通道数不会发生变化。,计算是按通道独立进行的。
- 对微小的位置变化具有鲁棒性(健壮)
输入数据发生微小偏差时,池化仍会返回相同的结果。因此,池化对输入数据的微小偏差具有鲁棒性
7.4 卷积层和池化层的实现 241
7.4.1 4 维数组 241
如前所述,CNN 中各层间传递的数据是 4 维数据。所谓 4 维数据,比如数据的形状是 (10, 1, 28, 28),则它对应 10 个高为 28 、长为 28 、通道为 1 的数据。用 Python 来实现的话,如下所示。
1 | |
访问第 1 个、第 2 个数据,写 x[0]、x[1]
1 | |
若要访问第 1 个数据的第 1 个通道的空间数据
1 | |
7.4.2 基于 im2col 的展开 242
麻烦地实现卷积:重复若干层 for
NumPy 中存在使用 for 语句后处理变慢的缺点(NumPy 中,访问元素时最好不要用 for 语句)。
简单地实现卷积:用 im2col 这个便利的函数
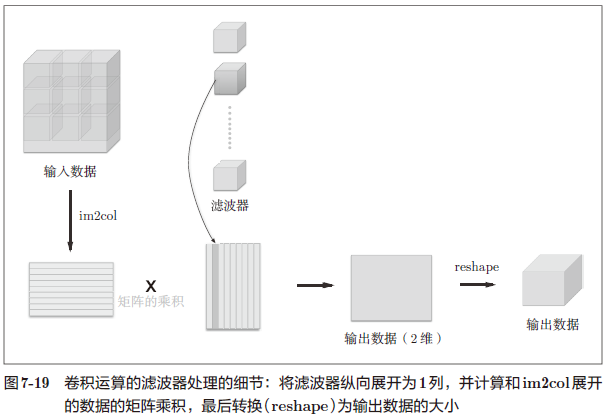
im2col 这个名称是“image to column”的缩写,翻译过来就是“从图像到矩阵”的意思
im2col 函数:将输入数据展开以适合滤波器(权重)
具体地说,如图 7-18 所示,对于输入数据,将应用滤波器的区域(3 维方块)横向展开为 1 列。im2col 会在所有应用滤波器的地方进行这个展开处理。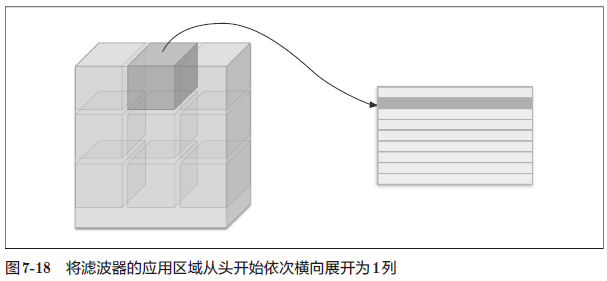
解释:
为了便于观察,设置的步幅较大,以使滤波器的应用区域不重叠。而在实际的卷积运算中,滤波器的应用区域几乎都是重叠的,在这种情况下,使用 im2col 展开后,展开后的元素个数会多于原方块的元素个数。因此,使用 im2col 的实现存在比普通的实现消耗更多内存的缺点。但是,汇总成一个大的矩阵进行计算,对计算机的计算颇有益处。
使用 im2col 将输入数据转化为矩阵后,与将卷积层的滤波器(权重)1 列列纵向展开构成的矩阵相乘,得到输出数据的矩阵,最后再把矩阵 reshape 为四维数组保存在 #CNN 中